Local Moderne MCP: Deterministic Tools for Coding Agents

Contents
Think about how a coding agent navigates your codebase. It uses grep to find patterns. It opens files. It reads them to figure out if what it found is actually relevant. Then it does it again and again and again.
Text search and file reading are the tools agents reach for most, and for a lot of everyday tasks they’re fine. But when the work requires understanding code semantics — finding every usage of a deprecated API through inheritance, tracing a dependency graph, migrating a framework across hundreds of files — the agent compensates for the limits of its toolbox with brute force. Grep, open, read, reason, repeat. Every cycle in that loop costs time and tokens, and the costs compound fast across a session.
The problem isn’t that the models aren’t smart enough. It’s that they need better tools.
We’ve written about agents as the primary consumers of dev tools and the opportunity to move work from GPU to CPU wherever possible. The Moderne CLI for agents is the toolbox that makes that practical.
One command for a full semantic toolbox
The Moderne CLI includes an MCP server that runs locally alongside your coding agent, giving it direct access to tools backed by a semantic model of your code. One command installs it:
mod config agent-tools install
The CLI auto-detects your agent (Claude Code, Cursor, Windsurf, GitHub Copilot, Sourcegraph Amp, OpenAI Codex) and wires in the right configuration. The next time you start an agent session inside a git repository, a local MCP server process starts in the background and a new set of tools becomes available. The server runs as a subprocess of the agent itself, communicating over stdin/stdout with no network listener. It exposes the same operations already available through the mod CLI, just in a structured form the agent can call directly.
Those tools cover two key things agents spend the most time (and tokens) on: searching the codebase and making changes to it.
Searching code, not text
If you watch an agent work, it searches a lot more than you’d expect. Not just when you ask it to find something, but constantly. It’s frequently checking assumptions, looking for usages, and figuring out what’s connected to what. The default tool for all of this is grep, and it works fine for small amounts of code, but every broad match means another file the agent has to open and read to confirm relevance. For large codebases, like the 5 billion lines of code or large monorepos we see at our customers, grep and similar searches simply don’t scale.
Moderne Trigrep changes that equation. It’s a trigram-indexed search that operates on a pre-built index rather than scanning files. Through the local MCP server, it’s exposed as two tools: trigrep_search for text, regex, and filtered queries with support for Zoekt-based symbol search, and trigrep_structural_search for Comby-style pattern matching across multi-token code structures. Queries return in milliseconds regardless of repository size.
Speed matters, but the more important improvement is precision. Because Trigrep’s index is built from Moderne’s Lossless Semantic Trees (LSTs) rather than raw source files, it carries structural metadata that a plain text index doesn’t have. The query syntax will look familiar to agents already trained on commonly-used code search tools, so there’s no new language to learn, but the filters go further.
Explore more
The Lossless Semantic Tree
How Moderne models code structure, type attribution, and formatting in a single compiler-accurate representation.
With extends:Person, the agent gets back only the classes that actually extend Person, not every file that mentions the word. Class inheritance, method visibility, return types, and thrown exceptions are all resolved from the type system in the LST. Without these filters, the agent has to open each matching file and read enough context to verify whether the match is structurally what it’s looking for. Semantic filters cut out most of those follow-on reads by giving the agent results it can act on directly.
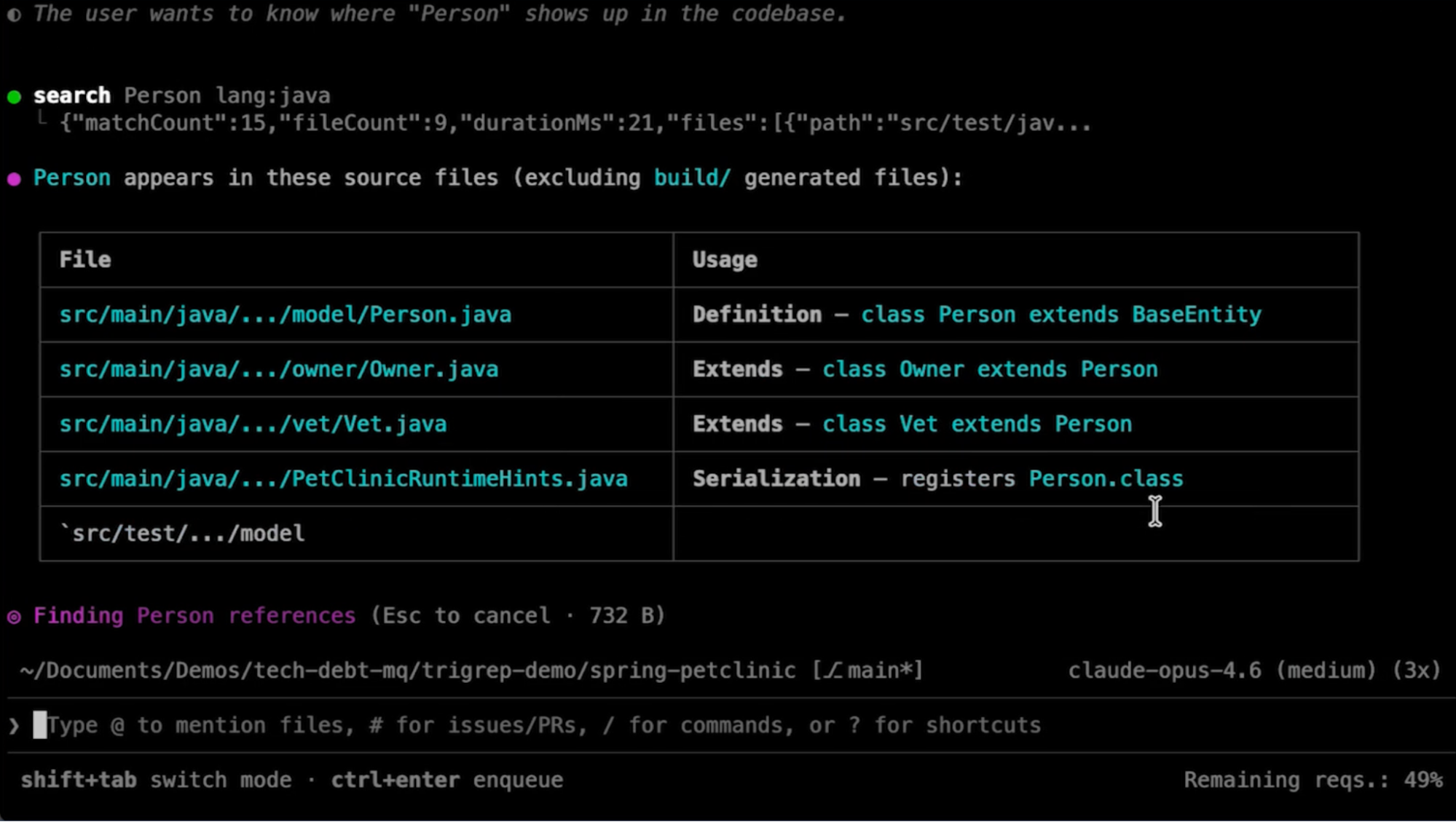
For even deeper analysis, the local MCP server also provides tools like find_types, find_methods, find_annotations, and find_implementations. These run Moderne’s full semantic analysis recipes under the hood, resolving through the entire type hierarchy. Where Trigrep with semantic filters gets you most of the way, these tools go further: tracing every reference to a type through its full inheritance chain, finding every invocation of a method across the call graph, with no ambiguity about whether a result is actually what you’re looking for.
They’re the complement to Trigrep’s speed. Fast indexed search for broad discovery, full semantic analysis when you need to be thorough. Both are available in the same session, and the agent can reach for whichever fits the question.
Let the recipes do the work
Search gets agents oriented, but the work that really burns through time and tokens is transformation. When the agent has to figure out a migration or refactoring from scratch, the process looks the same every time: read the files, understand the pattern, write the change, handle edge cases, file by file. That works for one-off changes, but it doesn’t scale when the same change needs to happen consistently across hundreds of files in a repository.
Moderne serves up deterministic recipes that provide semantically correct transformations. The OpenRewrite open source community contributes and maintains thousands of them, and Moderne’s own catalog adds thousands more that have been hardened over time across real enterprise codebases. The local MCP server gives agents direct access to this combined catalog through three tools:
search_recipesfinds relevant recipes by natural language query across nearly 7,000 options.learn_reciperetrieves the full details, including description, configurable options, and data table schemas.run_recipeexecutes a recipe against the repository. No AI is involved in recipe execution since recipes are deterministic, producing the same result every time given the same input.
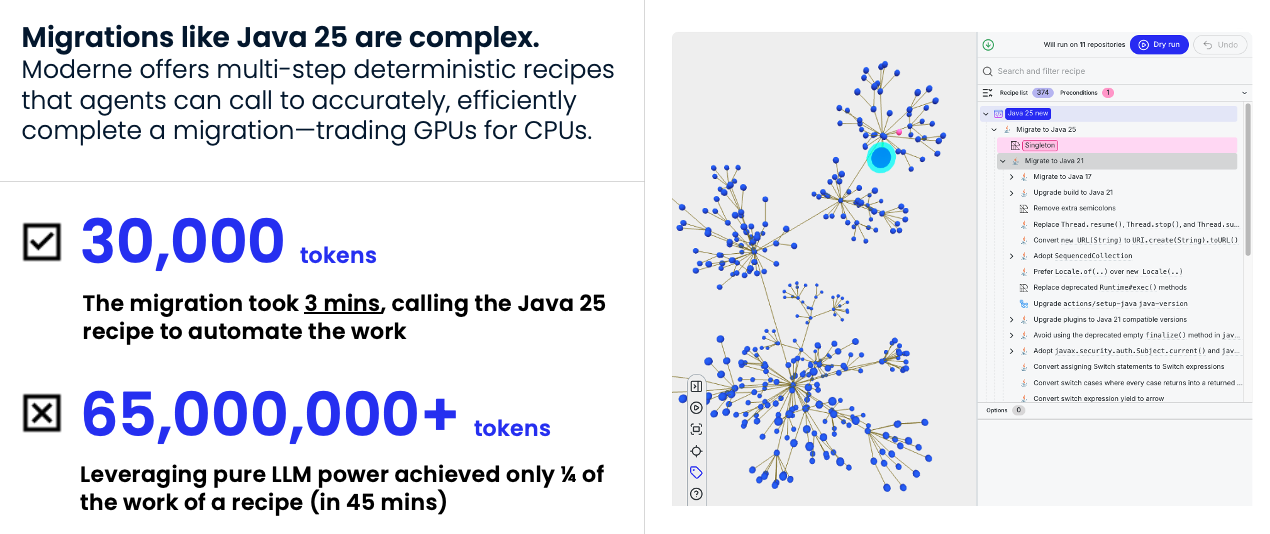
The difference is dramatic. In testing, an agent doing a Java 25 migration without Moderne’s tools burned through tens of millions of tokens with only about a quarter of the work completed. The agent was reading files, reasoning about each change, writing transformations, and missing edge cases. With run_recipe, the same migration completed in minutes using roughly 30,000 tokens. The recipe already encoded every transformation needed and applied them all deterministically. The agent spent its budget on the parts that actually required reasoning.
The local MCP server also exposes some commonly used recipes that are also available as direct tool calls, so the agent doesn’t need to go through the full search/learn/run cycle for frequent operations. change_type renames or moves a type across the entire codebase, updating every import, reference, and declaration. It’s what an IDE rename does, but available to the agent across the whole repo. change_method_name does the same for methods. pattern_replace runs Refaster templates for mechanical before/after code changes. This tool was added because an agent itself asked for it to make it more effective.
And when no recipe exists for the job, Moderne provides skills that teach agents how to write custom recipes. Once written, a new recipe is available to run like any other, turning a one-time inference cost into a reusable tool.
Agent tools on demand
Tools become available dynamically as they build understanding of your codebase. Here’s what that looks like.
After you’ve run mod config agent-tools install, a local MCP server starts automatically whenever you open an agent session inside a git repository. It immediately begins building two things in the background: the Trigrep index and a Lossless Semantic Tree. Both are built and stored locally so source code is never transmitted off the machine.
The Trigrep index comes up first, typically within seconds. At that point the agent has fast indexed search, already a significant upgrade over its default tools. The index starts without symbol information, so text search works but the semantic filters like extends: aren’t available yet.
The local MCP server then starts building the LST in the background. When that finishes, two things happen. The full suite of semantic tools comes online: find_types, find_methods, recipe execution, all of it. And the Trigrep index gets enriched with symbol information, so the semantic filters start working too.
The latest generation of the LST format, LSTv3, was designed specifically with this kind of agent-driven workflow in mind. Two capabilities matter most here:
Incremental compilation means that after the LST has been built, when the agent edits a file, only that file needs to be recompiled into the semantic model. The LST stays current as the code changes without a full rebuild. The agent edits, the model updates, and the next semantic query reflects the change.
Random file access means the server can jump directly to an individual file’s semantic representation on demand, without deserializing the entire repository. If the agent needs to understand a specific class, the tool can load just that file’s model rather than processing everything.
The agent itself has visibility into this process. build_status reports on the Trigrep index, and lst_status reports on the LST build. So the agent knows what’s ready and what’s still building, and can adjust accordingly: text search while the LST is still compiling, semantic tools once they’re available.
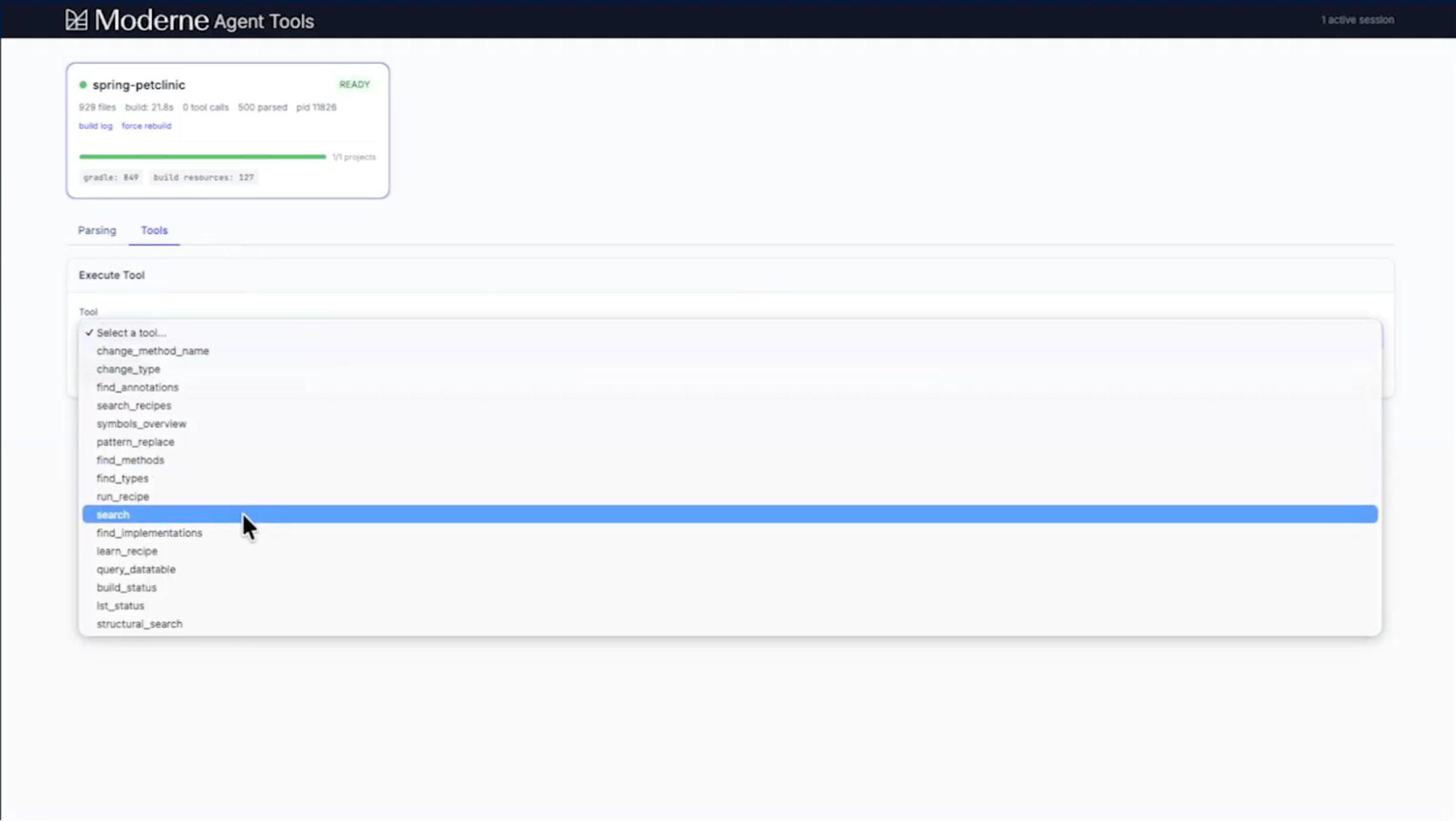
If you want a human-readable view of the same information, a tool browser is included with the local MCP server. On Mac, a system tray icon gives you access to a browser-based dashboard showing project cards with build status, file counts, and build logs with parse timing details. You can also test MCP tool calls directly from this browser dashboard. It’s a useful window into what the agent has access to and how it’s using it.
CPU instead of GPU
There’s a pattern running through everything here: the work that can be done deterministically should be done deterministically, so the agent can spend its inference budget on work that actually requires reasoning.
Pre-built indexes replace grep-and-read loops. Deterministic recipes replace hand-written transformations. Semantic filters replace file-read verification. Incremental LST builds replace full recompilation. Each of these swaps GPU for CPU as much as possible, trading expensive, probabilistic inference for fast, deterministic computation.
Moderne Prethink extends this same principle to codebase context. Instead of spending tokens at the start of every session while the agent explores your code to understand architecture, dependencies, and conventions, Prethink pre-computes that context using static analysis. The context lives alongside your code, can be versioned with it, and is made available to any agent on any machine without additional setup. No decisions about where to store it or how to sync it. It’s stored in the repo, when the agent starts, and can be dynamically updated as code changes.
This matters even more for code quality. Agents work well in well-structured codebases where patterns are consistent and conventions are clear. They struggle in codebases with accumulated inconsistencies, mixed patterns, and unresolved tech debt. Prethink’s code quality metrics give the agent structured feedback about the state of the code it’s working in like complexity hotspots and consistency gaps. Instead of generating code that looks fine in isolation but doesn’t match the surrounding codebase, the agent has a signal about what “good” looks like in this specific repo and can adjust accordingly.
As agent usage scales across more sessions, more repositories, and more engineers, the cost difference between the CPU and GPU approaches compounds. The organizations that get ahead of this aren’t the ones with the smartest agents. They’re the ones that give their agents better tools, so the model can focus on the work that actually needs it.
Get started
Give your coding agent better tools
Install the local Moderne MCP server and skills. One command, and the next agent session gets semantic search, deterministic recipes, and full LST analysis.
Related posts


