The first user of your dev tools is no longer a developer

Contents
- 1. Why coding agents waste tokens on code search (and how to fix it)
- The grep-then-read trap
- 2. Why coding agents spend two minutes doing what should take five seconds
- Context that agents have to rebuild from scratch, every session
- 3. How the right editing tools cut a Java migration from 65 million tokens to 30,000
- Editing at the wrong level of abstraction
- 4. How agent session transcripts reveal tool gaps
- The signal sitting in your transcripts
- The real cost of inefficient agent tooling
- Building dev tools designed for coding agents
Most engineering teams I talk to have now deployed at least one coding agent, and many are running several. What started as experimentation has moved into production, and that shift changes how I think about the tooling layer underneath.
The tools that engineering teams rely on were designed with the assumption that the user has context, patience, and the ability to interpret incomplete or ambiguous output. IDEs, linters, and code search were all built to work that way. Coding agents are now primary consumers of many of these same tools, but in practice they behave quite differently. They operate within hard constraints on tokens, execution time, and API cost, and every tool call draws from that budget. Whether a tool is developer-friendly matters less, at this point, than whether it is efficient for the agent consuming it.
It’s worth being precise about what kinds of work should fall to the model versus what should fall to tooling. GPU-backed computation is expensive, probabilistic, and rate-limited. CPU-backed computation is deterministic, fast, and cheap at scale. A significant portion of what agents are doing today (searching for code, reconstructing context, performing edits) is happening in the wrong place, and the opportunity is to move that work out of the model and into purpose-built tools. I think this is where the most meaningful engineering productivity gains are available over the next few years, and we’ve been working through it in four areas where we’ve seen real results.
1. Why coding agents waste tokens on code search (and how to fix it)
The grep-then-read trap
If you watch an agent operate, you’ll often see the same pattern: search for something, then read through a series of candidate files to confirm what it found. The cost isn’t in the search itself; it’s in the cascade of reads that follow, because a text-based query can only narrow scope so far.
A symbol-aware index changes this in practice. When an agent can express type constraints, method signatures, or annotation usage directly in the query, it can eliminate most of those follow-on reads before they start, because the index already carries the semantic information the agent would otherwise have to go looking for.
When you move beyond text search entirely to a representation of the codebase that captures types and full structural relationships, the gains compound further. Instead of searching for text that might indicate a Spring API endpoint and then reading files to confirm, an agent can ask for Spring API endpoints directly and get a precise, token-efficient answer, one that often reflects deeper understanding of the code pattern than any text-based search could surface.
It turns out the model hasn’t done less work; it’s done the right work, because the tool handled the rest.
Go Deeper: Agent-Optimized Code Search
Moderne Trigrep: Sub-Second, Token-Efficient Code Search for Agents
Trigram indexing and the LST make code search orders of magnitude more efficient for coding agents across large and multi-repo codebases.
2. Why coding agents spend two minutes doing what should take five seconds
Context that agents have to rebuild from scratch, every session
Search is one dimension of the problem. Context gathering is another, and in some ways the more expensive one. When an agent needs to understand how a component fits into a system (its dependencies, its callers, its architectural role) it typically reconstructs that understanding from scratch every time a session starts.
I watched Claude Code work through a task that required understanding a single entity in a large enterprise codebase. It took nearly two minutes and tens of thousands of tokens just to build that picture. The model wasn’t doing anything wrong; the context simply wasn’t there when the session started.
The obvious response is to pre-compute it, and, frankly, it was a customer that suggested this before we had thought to. On a regular cadence, before any agent session begins, CPU-only static analysis can trace the relationships between components and commit that knowledge directly into the repository alongside the code: structured markdown describing architectural patterns, evidence files in queryable formats that agents can work with through tools like DuckDB rather than loading into context directly.
That same entity understanding task, on a repository where this context had been pre-computed and committed, completed in about five seconds. At the scale of hundreds of repositories, that difference (a few seconds versus a couple of minutes) determines whether a workflow is practical or not.
Stop Making Your Agents Rebuild Context From Scratch
Moderne Prethink: Structured Context for AI Coding Agents
Prethink pre-computes structured codebase knowledge before your agent session even starts, cutting context-gathering time from minutes to seconds.
3. How the right editing tools cut a Java migration from 65 million tokens to 30,000
Editing at the wrong level of abstraction
The third area is where I’ve seen the starkest numbers. Always keen to experience things first hand, I worked on one customer codebase on an attempt at a Grails 2 to Grails 5 migration using Claude Code. Even after the bulk of the base language update had been handled deterministically by a Moderne OpenRewrite recipe, the remaining agentic work took over eleven hours on a single repository, and the same customer has 300 more applications waiting.
The problem is that most agents still reach for the same editing primitives by default: file reads, string replacements, line-level changes. For localized edits that’s workable, but for structural transformations across thousands of interdependent files, the agent will hit the same edge cases repeatedly and spend tokens each time to relearn what a more structured operation would already know.
I ran a direct comparison on one of our own repositories.
A Java 25 upgrade using Claude Code with a full marketplace of OpenRewrite recipes and an incrementally compiled Lossless Semantic Tree connected as tools took around 30,000 tokens and under three minutes. The same Claude Code in a separate session, without those tools, burned 65 million tokens and completed about a third of the migration in 45 minutes before I gave up.

What struck me most was a moment partway through that second session where the model started asking for exactly the kinds of higher-level operations it didn’t have access to. Even without the tools, it recognized it wanted them.

I think that’s the strongest signal yet that the boundary between what the model should do and what the tooling should provide is more distinct than most people assume.
4. How agent session transcripts reveal tool gaps
The signal sitting in your transcripts
The fourth area is the one that closes the loop. Every agent session produces a transcript that captures the full sequence of tool calls, decisions, and detours. Most teams treat these as logs, a record of what happened rather than a source of signal. In practice, they’re a detailed map of where agents are spending unnecessary time, where better tools could have been used, and where the same work is recurring across sessions.
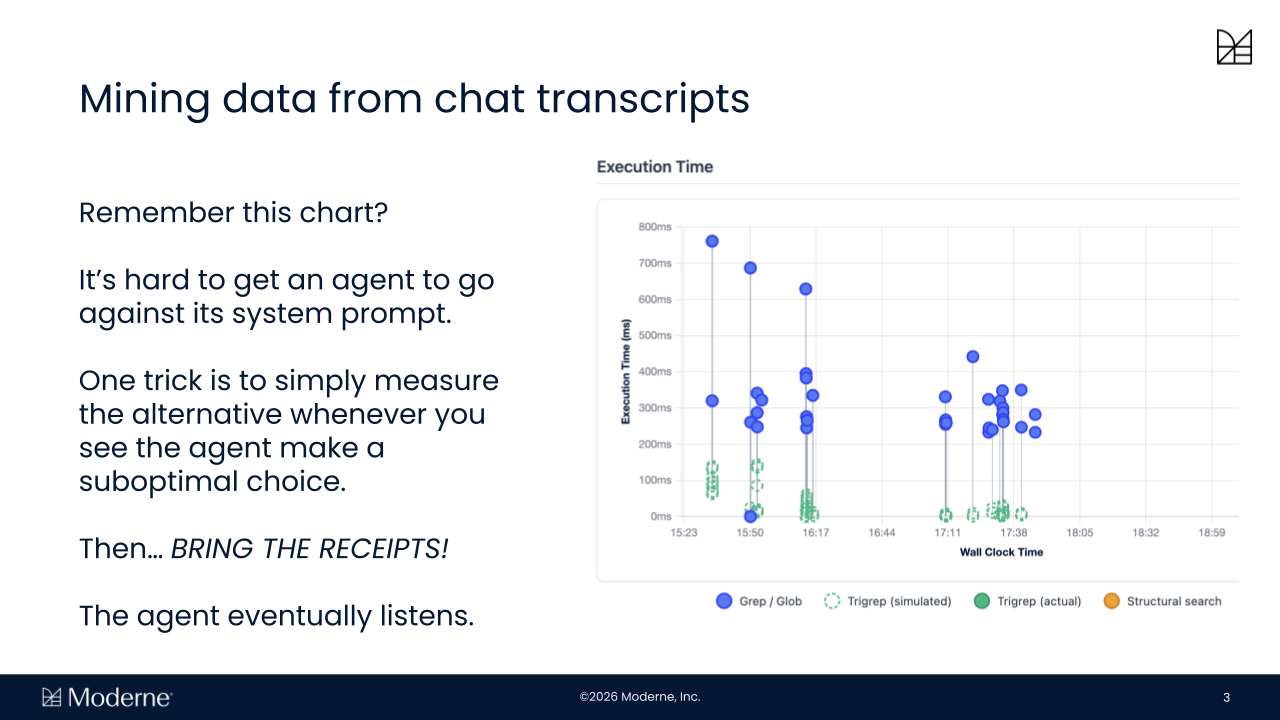
When those patterns are measured and the alternatives are benchmarked, the results can be fed back into the system in a way that influences future behavior, including through system prompts that give agents direct evidence of their own inefficiencies and the performance of alternatives. It turns out that agents, given the receipts, do eventually change their behavior. Over time, this creates a loop where tooling improves based on observed usage rather than assumptions.
The real cost of inefficient agent tooling
This becomes especially important as pricing models move toward consumption. I’ve been hearing from engineering leaders at some large enterprises that individual developers are burning through their monthly token quota within the first few days of the month, then going without for the remaining three weeks.
What looks like a marginal inefficiency at the level of a single task compounds quickly across large numbers of repositories and repeated agent runs. The difference between rebuilding context in every session and reusing pre-computed knowledge, or between editing at the string level and invoking a structured transformation, is where that budget actually goes.
In practice, every percentage gain in tool call efficiency, multiplied across an increasingly large agent fleet, shows up directly in cost and in how much work actually completes.
For those that don’t yet experience these token constraints, the lack of constraint is often a consequence of low to medium adoption through the engineering organization, but the constraint is inevitably drawing in as adoption goes up.
Building dev tools designed for coding agents
Most of the tooling we rely on today was designed for human workflows. Some of it translates well to agents, but much of it doesn’t, and that gap is widening as agent usage scales.
The question I keep coming back to is not how capable a given model is, but how much of the work it’s doing should have been handled by better tooling instead. At Moderne, that’s the question we’re building toward: not replacing coding agents, but making them viable at enterprise scale by providing the underlying operations they can rely on for search, context, transformation, and coordination, so that model-driven work is reserved for the parts of the problem that actually require it.
That gap is measurable, and in my experience it’s where teams doing serious agent work are spending a growing share of their attention.
Related posts


