Context engineering: why AI coding agents spend most of their tokens reading, not writing
Contents
- The conversation about AI coding agents has been about the wrong thing
- Why AI coding agents burn most of their tokens before writing any code
- What context engineering really is: the code already has the answers
- What 5-6x token reduction looks like in practice
- Extending context engineering for your organization’s patterns
- Code quality metrics agents can act on, not just dashboards humans triage
- What attendees said is hardest about AI coding agents today
- Selected questions from the audience
- Why CSV files in the repo instead of a database with an MCP tool?
- How do you keep precomputed context up to date as the code changes?
- How does Prethink combine with spec-driven development frameworks like OpenSpec or GitHub Spec Kit?
- Where Prethink goes next
The conversation about AI coding agents has been about the wrong thing
For most of the last two years, the discussion around AI coding agents has been about the agents themselves: better models, larger context windows, more capable tool use. What gets less attention is what those agents actually do with most of their tokens on a real enterprise codebase.
In our recent webinar, we walked through the pattern we see across customers and demonstrated it live. Most of what an AI coding agent does on a real codebase is not writing code. It is trying to figure out the code first. That work is expensive, repetitive, and almost entirely avoidable.
Speakers:
Bryan Friedman, Director of Technical Marketing at Moderne
Matt Campbell, Staff Solutions Engineer at Moderne
Why AI coding agents burn most of their tokens before writing any code
Watch what an agent does when you ask it to make a change in a codebase it does not know. It enters what we call the grep-read-grep-read loop: scan a file, follow a method call, scan another file, follow a dependency, repeat. Every one of those steps consumes tokens. The agent is not slow. It is spending most of its budget on context discovery before any actual generation begins.
The READMEs, CLAUDE.md files, and other agent config files most teams use to provide context help, but they are inconsistent, easily stale, and rarely capture what the agent actually needs: architectural boundaries, dependency relationships, security boundaries, test coverage gaps.
The token economics of AI coding agents are shifting fast. Subscription tiers that started with simple session limits have moved to weekly caps with overage pricing on top. The reason is that real codebases require a lot of expensive work that has nothing to do with code generation.
Related reading: AI writes code faster than teams can trust it. Quality context is the answer.
What context engineering really is: the code already has the answers
Context engineering is the practice of pre-computing the architectural and semantic information an AI Coding agent needs, then placing it where the agent will reach for it. Code is the context. The architecture, the patterns, the dependencies, the conventions, all of it is sitting in the repository already. The problem is the form.
When an agent reads a source file as text, it has to reconstruct everything the compiler already knows: which symbols resolve to what, which methods are called from where, which classes share dependencies. That work has been done. It just is not accessible in a form an agent can query cheaply.
Moderne’s lossless semantic tree (LST) is that resolved form. Symbols, types, method calls, dependency graphs, all already computed. Prethink is the recipe that takes the LST and turns it into a set of CSV and Markdown files that live next to the code, so an agent can query exactly the architectural information it needs without re-deriving it. The starter set covers service interfaces, test coverage, dependencies, coding conventions, and code quality. Language coverage today includes Java, JavaScript, TypeScript, and Python, with C# arriving soon.
What 5-6x token reduction looks like in practice
We ran a head-to-head demo. Same codebase (a Java e-commerce app), same agent (Claude Code), same question: “If I modify the order entity, what services would be affected?”
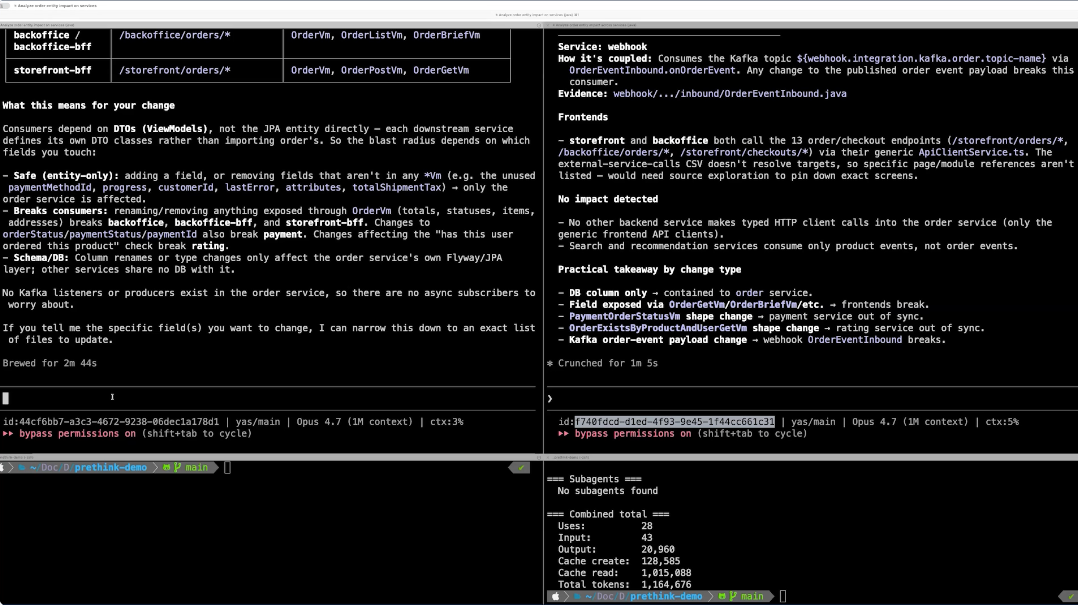
On the side without Prethink, Claude launched a sub-agent and started its grep-read-grep-read exploration. Two minutes in, it was still scanning YAML files. On the side with Prethink, Claude saw the available context files referenced in CLAUDE.md, used a DuckDB tool to query the relevant CSVs directly, and returned a precise impact analysis (order service, payments, ratings, webhooks) in about a minute.
The token comparison: the Prethink side used roughly one million tokens. The side without Prethink used five to six times as many. Matt’s framing during the demo: “Let’s defer that, let’s shift that left as far as we can, before anybody even opened Claude to begin with.”
The Prethink recipe runs without an LLM at all. No tokens spent generating the context. And once that context is in the repo, every developer on the team uses the same precomputed work instead of paying for the same exploration ten different times.
Related reading: The first user of dev tools is no longer a developer.
Extending context engineering for your organization’s patterns
The starter set of Prethink context covers what we have found valuable across enterprise customers. What is valuable beyond that depends on your codebase, your patterns, and your platform.
Matt walked through building a custom Prethink recipe in the Moderne platform. The example added two organization-specific contexts: instances of internal annotations (@RateLimited, @Auditable) and usages of an internal service client. The custom recipe combined these with the standard Prethink starter, then updated CLAUDE.md to tell the agent how to use the new tables.
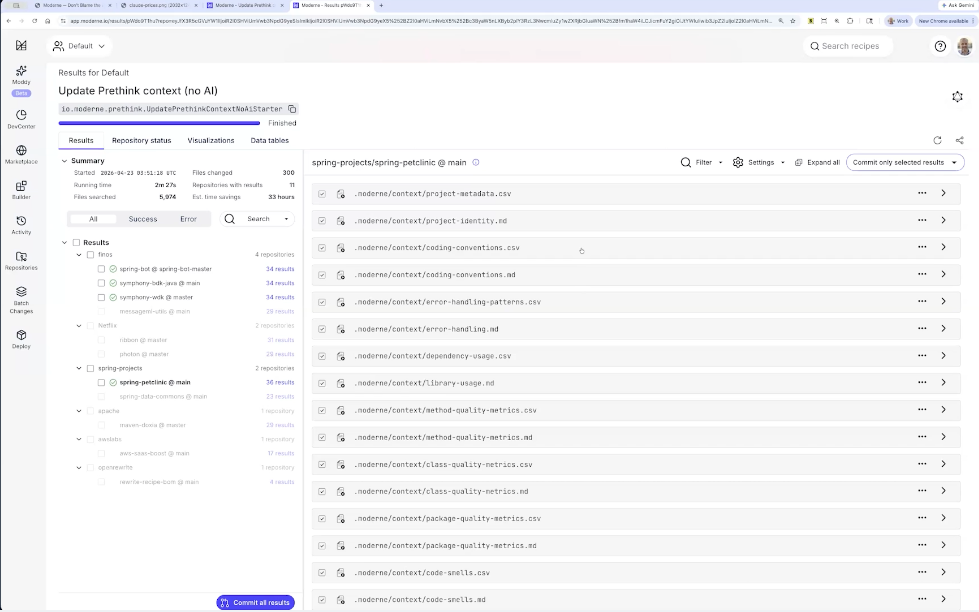
The test: ask Claude to build a new loyalty points API endpoint. Without the custom context, an agent writes something that looks correct but uses the wrong patterns. With the custom context, Claude reached for the rate-limited and auditable annotations and the internal service client, generating code that fit the organization’s conventions on the first pass. As Matt put it, this is how you turn the patterns “you bake into a shared library somewhere and hope somebody uses” into a well-trodden happy path your agents will actually follow.
Code quality metrics agents can act on, not just dashboards humans triage
Traditional code quality scanners ship results to a dashboard, where a human triages them. Meanwhile the agent is happily making changes in the same codebase, often making the existing problems worse.
Prethink captures code quality at three levels. At the method level: cyclomatic and cognitive complexity, nesting depth, statistical bug likelihood. At the class level: LCOM4 cohesion, coupling between classes. At the package level: incoming and outgoing dependencies, abstractness scores. All of it is written into the same context files agents already query.
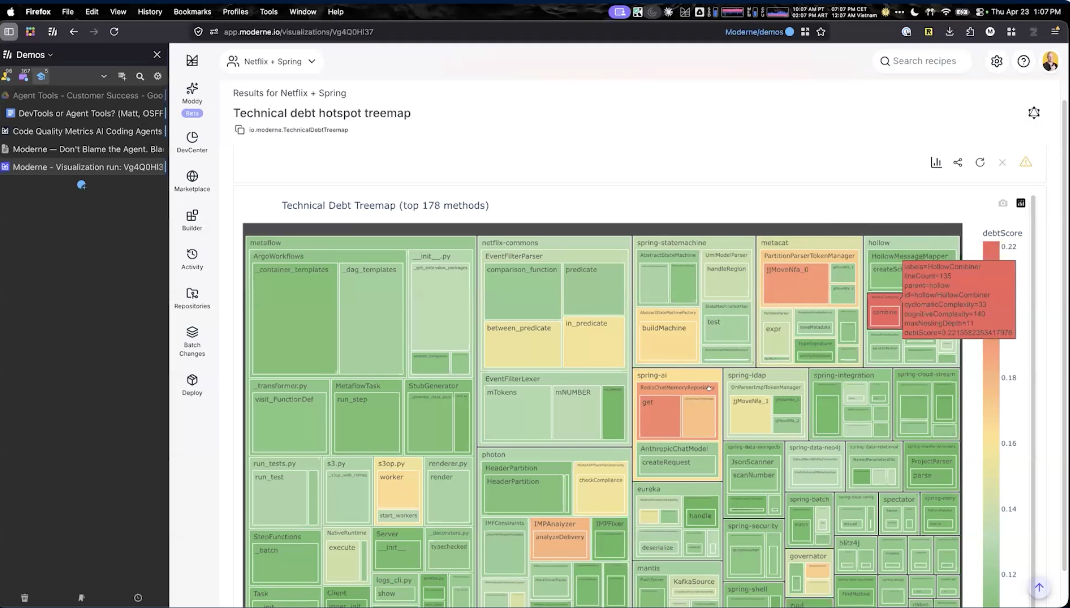
Matt demonstrated the heatmap across 200+ Netflix and Spring repositories. One example: Spring AI’s RedisChatMemoryRepository had a method nearly 300 lines long with a nesting depth of nine and high cyclomatic and cognitive complexity scores. With Prethink context in place, an agent asked to add functionality there gets a signal: this method is already in trouble, find a different home for the new logic. Combined with test coverage data, the agent can also be guided to write tests first when changing under-tested complex code, instead of layering new behavior on top of fragile foundations.
Related reading: Code quality metrics that AI coding agents can actually use.
What attendees said is hardest about AI coding agents today
We ran three polls during the session. The results from a self-selected technical audience:
Tools in use. Claude Code led at 67%, GitHub Copilot at 53%, Cursor at 23%, with Codex (OpenAI), Windsurf, and others trailing. Multi-tool environments are the norm, not the exception. Most respondents selected two or more tools.
Organizational maturity. 31% reported AI coding tools deployed organization-wide and focused on improving quality and consistency. Another 31% reported deployed-with-some-teams, still working out the kinks. 23% had individual developer use without formal rollout. Only 6% described themselves as mature, optimizing for reliability and cost. The center of gravity is clear: most enterprise teams have rolled out AI coding tools and are now in the harder work of making them reliable.
Biggest challenges. Two answers tied for first at 21% each: “agents struggle with our large, complex codebase due to lack of context” and “agents produce code that looks correct but doesn’t fit our architecture.” Combined, 41% of respondents named context as the root problem. Trailing answers (governance and review at scale, inconsistent quality across engineers, adoption) were each at 12%.

The poll data reinforces the webinar thesis. The hardest part of running AI coding agents at enterprise scale is not the agent itself. It is the context the agent has access to.
Selected questions from the audience
A few questions from the live Q&A worth surfacing:
Why CSV files in the repo instead of a database with an MCP tool?
The pattern works because agents are heavily focused on the repository they are operating in, so colocating context with code maximizes the chance they will reach for it. Recipes are customizable, so teams that prefer a database-and-MCP architecture can adapt Prethink to that pattern. The default reflects what we have seen work most consistently across customers.
How do you keep precomputed context up to date as the code changes?
The same way you would keep any generated artifact fresh: run the recipe on a schedule, or trigger it on merge to main. Cadence depends on how often the underlying code changes and how breadth-sensitive the context is. Most teams settle into a daily or per-merge cadence.
How does Prethink combine with spec-driven development frameworks like OpenSpec or GitHub Spec Kit?
Prethink writes its context into a delimited section of the agent config file (CLAUDE.md, AGENTS.md) and does not overwrite existing content. Specs and Prethink context coexist, giving the agent both the intent (from the spec) and the architectural reality (from Prethink) before it starts generating code.
Where Prethink goes next
Prethink is available now in the Moderne platform, including the customization and code quality recipes shown in this session. C# language support is on the way, joining existing support for Java, JavaScript, TypeScript, and Python. We are continuing to add new context modules and make it easier for teams to extend the framework with organization-specific recipes.
The shift Prethink represents is straightforward. Stop paying agents to rediscover your codebase on every query. Compute the context once, cheaply, off the critical path, and put it where the agent will reach for it. The agent gets faster, cheaper, and more accurate. Your team stops paying for the same exploration ten different times.
See Prethink in action
Stop paying agents to rediscover your codebase
Watch the full session, or book a working session to see Prethink generate context against a representative version of your own codebase.
Related posts


