From grep to Moderne Trigrep: Faster, token-efficient code search for agents and large codebases

Contents
- What’s in a name: Dissecting Trigrep search technology
- Why code search is a big deal to coding agents
- What developers and agents actually search for
- Using Trigrep search as a prefilter for large-scale automation
- What makes Moderne Trigrep search different
- Infused with Lossless Semantic Tree (LST) data
- Scoped to organizational structure
- Integrated with automation workflows
- How Moderne Trigrep compares to other search approaches
- Trigrep code search is infrastructure for the agent era
Developers have always searched code to understand systems. Coding agents do this even more, constantly probing repositories to orient themselves. These quick searches can happen every few seconds as agents adjust course, validate assumptions, and move tasks forward. Each pass can consume precious tokens, compute cycles, and seconds of latency. And those seconds add up.
Agents need to search more efficiently.
Moderne Trigrep is a high-speed, enterprise code search tool delivering responses in sub-second time enabling humans and agents to quickly locate what matters across large and multiple repositories.
As Moderne expands its role as the Agent Tools company, we’re building the infrastructure coding agents rely on to operate at scale. What makes Trigrep foundational for agent workflows—and why does discovery suddenly matter so much? Read on.
What’s in a name: Dissecting Trigrep search technology
The name “Trigrep” reflects both the technology and the experience. The “tri” refers to trigram indexing—a proven, decades-old technique for fast text discovery that replaces repeated file scanning with indexed lookup. The “grep” signals the familiar workflow developers (and now coding agents) rely on every day: quick search to orient before acting.
What makes trigram indexing powerful is how it changes the scaling problem. Instead of scanning every file for every search, queries intersect posting lists in a persistent index. In practice, searching a billion lines of code can take roughly the same time as searching thousands.
Moderne’s implementation builds those indexes from text or from the Lossless Semantic Tree (LST) code model. When the index is built with LST data, the index isn’t just fast—it has access to symbol information, type data, and other semantic details that wouldn’t be available from text alone. Searches can combine simple text discovery with structural filters, enabling queries that would be fragile or impractical with text-only tools.
It is this precision that makes Trigrep faster and more token efficient than the already very fast ripgrep that Claude Code often uses, for example. Lacking precision, Claude Code often greps and then follows that grep by expensive reads to confirm a match has the type it is looking for. The Trigrep symbol-aware search avoids the need for subsequent reads.
Under the hood, Trigrep uses a Zoekt-compatible index format optimized for scale. Trigrams pack three Unicode codepoints into a compact 64-bit representation, posting lists are delta-encoded for efficient compression, and the resulting index typically occupies only about 10–20% of the original source size. This keeps discovery fast, even across large application portfolios.
Indexes are also aligned with the organizational structure built in the Moderne Platform (i.e., repos.csv). This means searches can be scoped to specific teams, business units, or application portfolios rather than spanning every repository indiscriminately. The result is fast, focused discovery that developers and coding agents can immediately act on—whether they’re exploring code, preparing automation, or validating changes at enterprise scale.
Why code search is a big deal to coding agents
Coding agents are constantly reaching for search: grep, glob, awk repo by repo. Think of it like triangulating their position. Each search narrows uncertainty until the path forward becomes clear.
This changes the economics of software discovery. Every search carries a cost: tokens consumed for reading and reasoning, compute cycles spent processing results, and latency that slows feedback loops. Costly reads are often required after a grep-style search because the matches are overly broad, forcing agents to open files repeatedly to confirm relevance.
Imprecise search results also compete for limited context window space, crowding out more relevant information, reducing model effectiveness and increasing token consumption. That’s why agents often use separate subagents or retrieval steps to avoid overwhelming the primary reasoning context.
For a human developer, those costs are mostly invisible. For agents operating autonomously—often performing dozens or hundreds of searches or sub-searches during a single workflow—they compound quickly.
At scale, inefficient discovery becomes a real operational expense. Context windows consumed with irrelevant data. More tokens burned. Slower iteration. And ultimately, less efficient, costly automation.
Sub-second indexed discovery with Trigrep flips that equation. By making code search effectively instantaneous and more precise, it reduces reasoning overhead before the first line of automation runs. Agents can orient faster, focus their analysis, and spend more of their effort on meaningful change rather than repeated exploration. We tested out Trigrep calls against grep/glob to compare response times. As they say, the results speak for themselves: Moderne Trigrep is 13.5x faster than ripgrep on average.
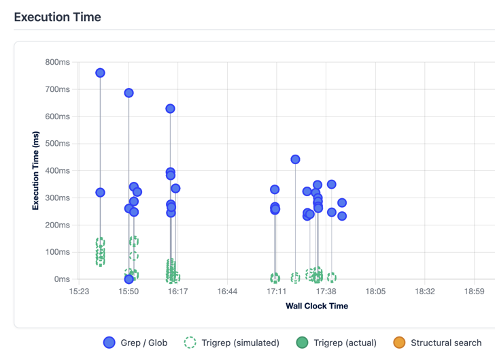
In an agent-driven development environment, search speed isn’t just a convenience. It’s a foundational efficiency layer.
What developers and agents actually search for
At its core, Trigrep is about finding text—quickly and with enough context for action. Importantly, it supports the same syntax for command line searching as other trigram-based search tools. This common point of reference enables models trained to use those commands to easily adapt to Trigrep. These searches typically take a few forms:
Literal text queries – Finding where a specific string appears, such as a function name, configuration value, dependency reference, or error message
Regular expressions (regex) – Spotting patterns across repositories, naming conventions, version usage, or repeated code fragments
Structural patterns – Combining text discovery with awareness of code syntax to locate constructs that would be fragile to match with text alone
The goal isn’t deep analysis at this stage. It’s fast reconnaissance to understand where something exists before deciding what to do about it. Trigrep is often the first step, helping quickly narrow scope before deeper semantic analysis, generation, or refactoring begins. Some examples include:
Dependency and usage signals – Searching for import statements, dependency coordinates, configuration keys, class or API names, annotations, or framework-specific terminology helps quickly identify where a technology or pattern likely appears.
Security and compliance indicators – Text search can quickly surface vulnerable version strings, credential-like patterns, deprecated APIs, configuration flags, or policy-related keywords that warrant closer inspection.
Modernization and upgrade reconnaissance – Searching for framework names, version identifiers, deprecated constructs, or configuration conventions helps estimate the potential scope of upcoming migrations or changes.
Debugging and incident clues – Searching error messages, log fragments, configuration names, or stack trace text often provides the fastest way to locate relevant code or related references during an investigation.
After searching for text, humans and agents have narrowed the scope and can proceed to detailed semantic analysis and deterministic transformation as required.
Using Trigrep search as a prefilter for large-scale automation
Executing semantic search or automated code transformations across large repository portfolios can be compute-intensive. When an OpenRewrite or Moderne recipe is running against an organization set, Trigrep indexed search provides a fast prefilter, reducing scope before detailed analysis or change execution starts.
For example, consider a recipe designed to identify Kafka producers. It might look for KafkaTemplate method calls, @SendTo annotations, Kafka Streams types, or direct KafkaProducer usage. Running that recipe across thousands of repositories means reading every codebase LST, even though most may not use Kafka at all.
With Trigrep, you can search first to identify repositories that contain relevant patterns, then run the recipe against that filtered set. The search completes in seconds, while the automation runs only where it’s likely to produce results. If your search found matches in 47 repositories out of 10,000 total, the recipe run processes 47 repositories instead of 10,000. That’s a 99.5% reduction in work (and faster outcomes).
This prefilter pattern is especially powerful for modernization and migration work. Before updating deprecated APIs, upgrading dependencies, or enforcing new policies, teams can quickly assess scope, confirm assumptions, and target automation precisely. Search becomes the step that makes large-scale change faster, cheaper, and more predictable.
The same approach also helps validate outcomes. Search results can serve as a checklist, confirming where patterns existed before a change and verifying that automation addressed them afterward.
At enterprise scale, eliminating unnecessary work is often more impactful than simply parallelizing it. Fast discovery allows teams and agents to focus automation effort where it matters most, reducing compute overhead while increasing confidence in large-scale code evolution.
What makes Moderne Trigrep search different
Fast code search isn’t new. What matters is how that speed translates into actionable context at enterprise scale. Moderne Trigrep combines high-speed trigram indexing with organizational scoping and direct integration into automation workflows. Together, those capabilities turn quick discovery into a practical foundation for large-scale software evolution.
Infused with Lossless Semantic Tree (LST) data
Traditional indexed search tools work purely from raw source text. Trigrep can be built from the LST, a compiler-accurate representation of code that preserves structural and symbolic information. This means search results aren’t just fast; they carry added context for smarter filtering later and create a smoother path from discovery to analysis and automation without reprocessing the code from scratch.
Scoped to organizational structure
Most code search tools return results across everything they index or require users to supply a list of repositories ad hoc. That can be useful for exploration, but in enterprise environments it often produces unnecessary noise. Trigrep aligns search scope with how enterprise teams actually build and manage software. Searches can start within a business unit, team, application portfolio, or modernization initiative instead of spanning every repository indiscriminately. This keeps discovery focused and makes results immediately actionable for both developers and coding agents working across large software estates.
Integrated with automation workflows
Trigrep connects directly to automation. Search results can feed into recipes as prefilters, allowing teams to target transformations precisely rather than running analysis across every repository. This reduces unnecessary compute, shortens execution time, and increases confidence in large-scale changes. Fast discovery becomes the first step in a continuous cycle: search to understand scope, analyze with semantic precision, then automate safely at scale.
How Moderne Trigrep compares to other search approaches
Different search tools serve different purposes. Trigrep is designed specifically for instantaneous discovery with the added bonus that it can lead into deeper analysis or automation.
| Tool type | Technique | Strengths | Limitations |
|---|---|---|---|
| Grep family (grep, ripgrep, ag) | Raw text scan | Simple, local, immediate | Re-scans files each time; more reads required to confirm matches; very slow for large repos |
| Indexed code search tools | Trigram indexing | Fast discovery across many repos | Often limited integration with automation workflows |
| Semantic search (Moderne recipes) | Search LSTs via recipes | Precise understanding and transformation | Slower scan due to deeper analysis |
| Moderne Trigrep | Trigram indexing with LST data and org scoping | Fast, contextual, automation-ready discovery | Designed for fast discovery, not full semantic analysis |
Trigrep code search is infrastructure for the agent era
Trigrep search is like Formula 1 racing, the advantage isn’t just speed—it’s speed on the right line. Agents are able to orient faster, reduce token consumption, and automate change more efficiently across entire software portfolios.
That’s where Moderne’s broader agent tooling strategy comes together. Moderne Trigrep delivers high-speed, targeted discovery. Moderne Prethink provides persistent architectural context derived directly from code. And Moderne recipes are the deterministic action, enabling safe, large-scale change once scope is understood.
Together, they help agents Discover → Understand → Act at portfolio scale.
Search, in this sense, is becoming infrastructure. It’s the entry point to automated, portfolio-scale software evolution, helping organizations move faster while maintaining control, efficiency, and confidence in how their software systems change.
Check out the documentation to learn more about Moderne Trigrep and how to get started.
Related posts


