AI writes code faster than teams can trust it: Quality context is the answer

Contents
Coding agents are genuinely impressive. They write functions, refactor classes, migrate dependencies, and generate tests faster than any human team. That’s not a criticism. That speed is the point.
But speed without context is how you end up with agents confidently modifying a method that has a cyclomatic complexity of 47, zero test coverage, and 200 call sites depending on it. The agent didn’t know. Nobody told it.
That’s the trust problem teams are running into right now. It’s not that AI writes bad code. It’s that AI writes code faster than the quality guardrails most organizations have built were designed to handle.
The dashboard was built for humans
Most engineering teams have a code quality tool. It scans the codebase, reports findings to a dashboard, and a human reviews them periodically. This model has worked reasonably well for a decade, when humans were the only ones writing code.
Agents work differently. They open files, read context, write changes, and move on. When an agent is deciding how to modify a class, it has no way of knowing that class has an extremely low cohesion score of 0.05, or that it’s one of the most-coupled objects in the entire package, or that every method in it lacks test coverage. That information exists, just not where the agent is looking.
The result is agents making technically correct changes that are architecturally wrong. Modifications that pass CI and break the design. Code that works today and becomes unmaintainable in six months.
The fix is not more prompting—it’s quality context
The instinct is to solve this with better prompts. Tell the agent to “follow clean code principles” or “check for test coverage before modifying.” This doesn’t work at scale.
An agent prompted to consider code quality has to infer what that means for your specific codebase, in this specific class, at this specific moment in time. Every session starts from scratch. The agent spends tokens reconstructing context that already exists somewhere, just not in a form it can read.
The better approach is to make quality context explicit, deterministic, and present in the repository before the agent starts: the knowledge of where high-risk complexity lives, what the architecture looks like, and where the gaps in test coverage are.
Moderne Prethink
Give your agents the quality context they’re missing
Prethink surfaces code quality metrics as structured files in your repository, where agents read them automatically before writing a single line.
What it looks like when agents have quality context
Moderne Prethink works through a set of Moderne recipes that analyze your codebase and materialize the results as structured files directly in the repository, in CSV and Markdown. Agents can consume the data automatically every session, without inference overhead, through CLAUDE.md or .cursorrules. Each recipe targets a specific layer of quality: method complexity, class cohesion, package coupling, code smell detection, test gap risk. Each writes its output to .moderne/context:
.moderne/context/
method-quality-metrics.csv # 56,000+ methods with all metrics
class-quality-metrics.csv # 2,900+ classes with WMC, LCOM4, TCC, CBO
package-quality-metrics.csv # 514 packages with coupling, cycles
code-smells.csv # God Classes, Feature Envy, Data Class
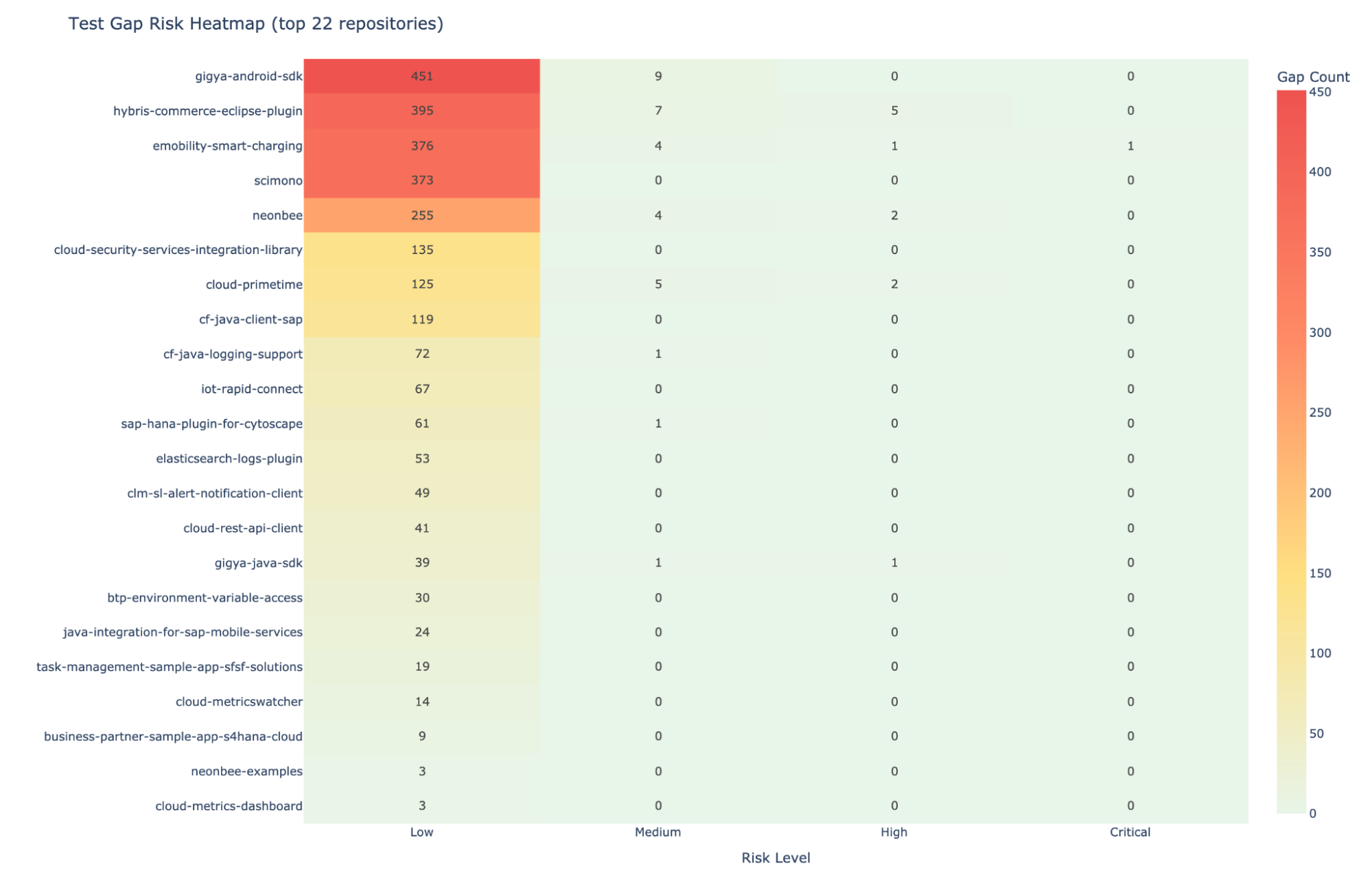
test-gaps.csv # Untested methods ranked by risk
When an agent opens the repo, it already knows:
**Which methods carry the most risk. **A composite debt score combines cyclomatic complexity, cognitive complexity, nesting depth, and defect density. The agent knows which methods need simplification before modification, not after.
**Which classes should be split. **LCOM4 cohesion analysis identifies classes with independent method groups that don’t share state. LCOM4 = 3 means the class has three independent clusters and should be three classes. The agent knows this before it adds a fourth method.
**Which packages are architecturally fragile. **Dependency cycle detection and instability scoring surface the packages where a change triggers a cascade. The agent knows not to introduce new cross-package dependencies into a package that’s already in a cycle.
**Where the riskiest test gaps are. **Test gap analysis ranks untested methods by risk score: complexity multiplied by call count. An untested method with complexity 23 and 40 callers is a much bigger problem than an untested getter. The agent knows the difference.
In an analysis of a large enterprise open source portfolio spanning over 100 repositories, nearly half of all packages contained circular dependencies. The same analysis found 5,745 instances of Feature Envy, methods sitting in the wrong class, quietly making the codebase harder to change. Most of those codebases had quality tools. None of the tools were putting that information where agents could use it.
Quality metric visualizations on the Moderne Platform
The same recipes that produce agent-consumable CSVs also power a set of Python notebooks available in the Moderne Platform. These notebooks turn the raw metrics into treemaps, coupling-cohesion scatter plots, stability-abstractness diagrams, and test gap heatmaps. For teams that want to study quality trends across a portfolio, dozens or hundreds of repositories in a single run, the notebooks are where that analysis lives.
The two surfaces serve different audiences. The CSV files are for agents. The notebooks are for the engineers and architects who want to understand the codebase at a scale no dashboard was built for.
The difference between measurement and context
Traditional quality tools measure code and present findings on a server, a dashboard that humans triage when they get around to it. That model doesn’t translate to agent-driven development. Agents work inside the repository, reading files to determine their next move. Prethink puts quality intelligence there too.
The metrics go deeper than most static analysis tools offer: cognitive complexity, cohesion, coupling, Halstead information density, risk-scored test coverage gaps. The output format is structured data agents consume natively. Computed once, that context is available to every agent session without spending tokens rediscovering it from scratch.
The result is that an agent working on your codebase carries the same quality awareness your most experienced developer has built up over years: which classes are overburdened, which methods are untested risks, which packages are architecturally tangled, and what to do about each one. With AI writing code faster than teams can trust it, the answer isn’t to slow the agents down. It’s to give them the judgment they’re missing.
Quality measurement tells you where you are. Quality context tells your agents where to go.
Related posts


