AI coding agents don’t need bigger models. They need better tools.

Contents
- Coding agents are solving the wrong shape
- The density mismatch between models and code
- 30,000 tokens vs. 61 million tokens, same task
- The agent without the tool
- The agent with the tool
- Local MCP is the delivery vehicle
- Prethink: deterministic context, computed in advance
- Trigrep: near-constant-time code search the agent can rely on
- The systems of record the agentic SDLC still needs
- Changelog
- Transcripts
- Artifacts
- From individual agents to an industrial park
- The tools layer, built
Coding agents are solving the wrong shape

The image above is a graph of all the compositional recipes required to migrate a real codebase from Spring Boot 2 to Spring Boot 3 to Spring Boot 4. Jonathan Schneider drew it on stage to make a point that the rest of the talk built on: every business problem has a shape, and the tool meant to solve it needs to match that shape.
Some problems have simple shapes. “Change a type from X to Y” is a small puzzle piece. An inference-only coding agent can usually find a small puzzle piece on its own. Other problems look like the graph above. A coding agent that’s been handed a Spring Boot 4 migration ticket and told to just go figure it out is being asked to fit a complex shape with whatever tools it can scrounge from a text file.
That’s why the success rates of frontier inference-only systems on real enterprise migrations cap out around 30 to 40 percent. Not because the models aren’t smart enough. Because the shape doesn’t fit.
The actual shape of the business problem is so complex in its own right. We can’t just be a system where you’re running a recipe or running an agent to do a thing. We need to figure out a way to expose all of these recipes and the data behind them as tools for an agent to drive directly.
— Jonathan Schneider, CEO & Co-founder, Moderne
The density mismatch between models and code
For most of software’s history, the human-facing interface for code was an IDE. IDEs have done plenty under the hood for decades, but the surface a developer actually read and edited was mostly plain text. A developer opened one file at a time, derived an understanding of how the parts connected, and made changes. That worked because the human brain was also doing the connecting across files and modules.
Coding agents inherited the same text-based surface, without inheriting the human brain that did the connecting. The scale of the mismatch is plain: GPT-2 XL had 1.5 billion parameters; Opus 4.7 is estimated at around 5 trillion. A machine of that computational density still mostly reads code the way a developer reads code, by opening files. Density mismatch is the right name for what happens next. The model is dense. The data it’s reading is sparse. The grep-then-read-then-read-then-read pattern that dominates agent traces is the consequence.
A density mismatch is the gap between a model’s computational density and the plain-text surface it reads code through. A model estimated in the trillions of parameters opens one file at a time, then another, then another. That is the same access pattern a developer used in an IDE. The result: the agent burns tokens grepping and reading instead of querying a representation that already encodes the answers. The Lossless Semantic Tree closes that gap.
And the agent has no choice. If it wants to confirm that a logger field actually comes from the type it expects, it has to open the next file, and the next, and the next. Each read costs tokens. None of the reads produce a structured representation it can keep referring to. The next session starts from zero.

A model with this much computational density is interacting with one of the most basic possible representations of the thing it’s meant to analyze, the raw text, because that’s all it’s been given. The information loss between systems of such different densities is where the inefficiency lives. A model that can reason across an entire codebase needs a representation of that codebase that’s denser than the raw text.
Moderne’s answer is the Lossless Semantic Tree (LST). The LST captures everything the compiler knows about a codebase, including all the types, all their super-types and super-interfaces, all the references and call sites, and all the relationships across files and modules. It’s a representation built for the density of the model on the other side.
The Lossless Semantic Tree is OpenRewrite’s compiler-accurate model of a codebase. It captures the types, their super-types and super-interfaces, every reference and call site, and the relationships across files and modules, not just the text. It is the dense, structured representation that lets coding agents query code by symbol instead of grepping it as raw text.
30,000 tokens vs. 61 million tokens, same task
The clearest illustration of the density mismatch was a live demo: two coding agent sessions, same task, upgrade a moderately sized Java repository to Java 25. Same starting state, same git history, cleared context. The only difference: whether the agent had access to a tool that matched the shape of the work.
The agent without the tool
The first agent had Opus 4.6 and no access to the recipe library. It started by updating the build files. Then it declared itself successful.
When pushed on the fact that the source code hadn’t changed, it produced the response coding agents always produce in that situation: “You’re right, that’s just the trivial part, the real work is actually updating the parser.” Then it launched multiple plan agents. Then it researched on the internet what Java 25 means. Then it came back proposing to use a third-party tool. When told to do the work itself, it offered to grep and replace one pattern at a time.
Jonathan stopped it after 45 minutes. Four of fifteen tasks complete. The session had burned 61 million tokens: 46.2 million on the main conversation, 14.3 million on streaming events, and the rest across subagents, over 771 turns. For a task it never finished.

Have you ever tried to do a transformation that requires a lot of the same kind of change, even with frontier models? They resist it. They like to do the first several, and then they like to go sit on the beach.
Jonathan Schneider
Jonathan put the moment through the lens of a line from Sam Altman, who described OpenAI as “a token factory… I mean an intelligence factory.” We know what you mean, Sam. The slip is the point. From the seller’s side, the unit is the token. From the buyer’s side, paying for 61 million tokens for an agent that declared itself done, then chased residuals, then gave up, is not the same thing as paying for outcomes. The industry needs to find ways to change that dynamic. Selling tokens isn’t the same as selling done work.
The agent with the tool
The second agent had the same Opus 4.6 model and the same Java 25 task. The only addition was a local MCP server that exposed Moderne’s recipe library as callable tools. The agent was asked, in plain English, to upgrade the repository to Java 25. No mention of OpenRewrite. No mention of Moderne. No mention of recipes.
The model recognized that a Java 25 upgrade is a complex, multi-step transformation. It reached for a tool that matched the shape of the problem: the OpenRewrite Java 25 upgrade recipe. The recipe ran. About 700 files changed. The task completed in roughly three minutes and consumed about 30,000 tokens. The work was actually done.
A recipe is a deterministic program that runs once and finishes. A prompt is an inference that runs every time and resolves differently each time. For a transformation with a known target, an agent that calls a recipe spends tokens on the decision to call it, not on regenerating the change token by token. That’s why the tool-assisted Java 25 run finished in about 30,000 tokens while the inference-only run passed 61 million without finishing.
Local MCP is the delivery vehicle
If the LST is the dense representation and the recipe library is the tool surface, the delivery question is: how does the agent actually get to either of them?
Moderne made the unpopular choice: local MCP, not remote. An MCP server installed once on a developer’s machine. When the developer launches a coding agent (Copilot, Claude Code, Codex, Kiro, any of them), that agent spawns a local MCP server next to it. The server incrementally compiles the codebase into the LST, keeps it warm, and exposes thousands of recipes and queries as tools. Nothing leaves the box. The traffic is local. The data is local. The agent gets dense, structured access to its own codebase.
The local pattern also opens a feedback loop the remote pattern doesn’t. The MCP server is sitting next to the coding agent for the entire session, whether or not the agent is calling it at a given moment. It can watch what the agent is doing. It can learn which tools are getting reached for, which descriptions are unclear, which capabilities the agent doesn’t realize it has. The server gets better the more the agent uses it.
Prethink: deterministic context, computed in advance
The next move beyond “give the agent dense tools” is “give the agent dense context before it ever opens a session.” That’s Prethink.
A Prethink job runs a recipe across the codebase ahead of time and emits the results as a data table. Plain rows and columns. The table might list every deprecated Spring API in use, with file, method, type, and call site. Or every test gap. Or every god class. Or every place a particular architectural pattern is or isn’t followed. The output is a checked-in artifact the next coding agent can read, instantly, without having to derive any of it.
In one demo, the agent is asked, “If I modify the order entity, what other services might be affected?” Without Prethink, two minutes of grepping and reading. With a Prethink table checked into the repo: five seconds. Same model. Same agent. The only difference is whether the context was computed in advance or had to be reconstructed on the fly.

Why this matters: recipes are programs anyone can write, including agents. Which means the context an agent gets isn’t fixed at the model layer. It’s something the organization controls. Whatever architectural fact about the codebase the agent needs to know to be useful, that’s a recipe you can write once and let the agent rely on forever.
If you think of Prethink as a recipe, and recipes are something an agent can write or you can write, you’re completely in control then of the kinds of context that your agents are exposed to.
Jonathan Schneider
Trigrep: near-constant-time code search the agent can rely on
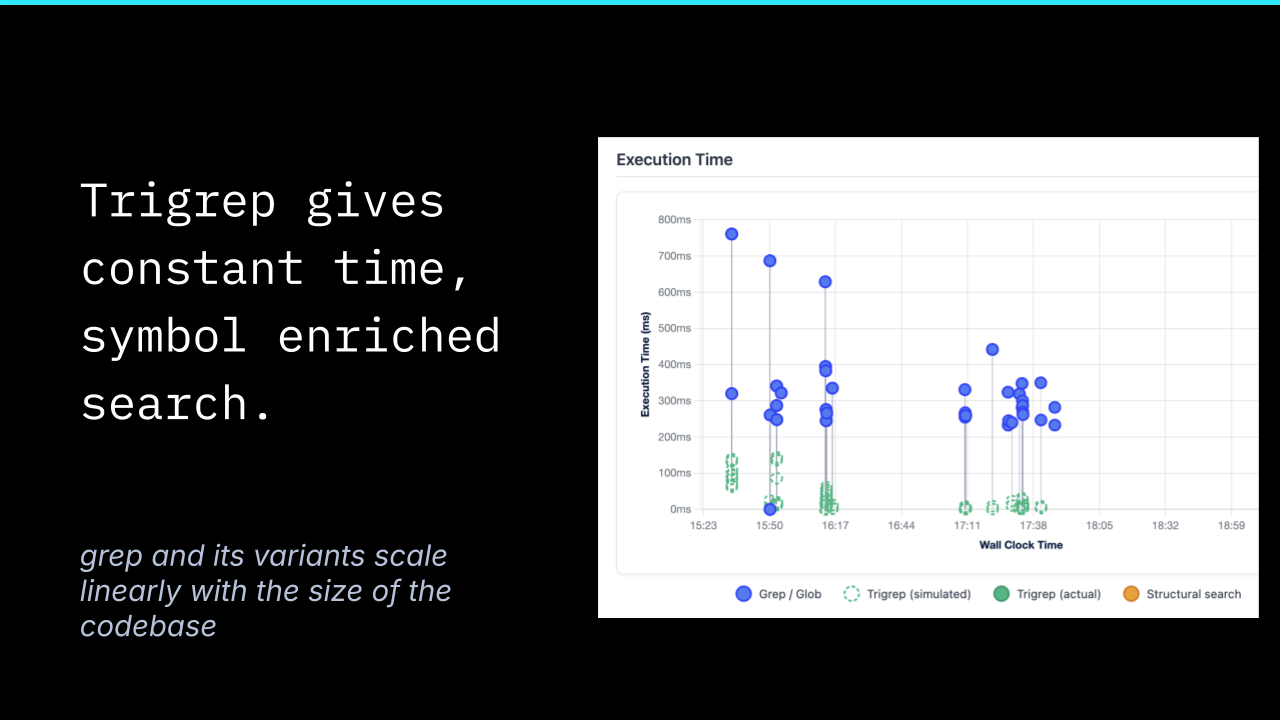
The other piece of the agent’s toolbox is Trigrep. Trigrams are an old idea (three-character substrings used as an index), and they’re the technique behind both GitHub code search and Google’s internal code search. The reason they’re worth pulling forward for coding agents is performance: trigram indexes give constant-time search on a codebase, no matter how large.
Grep is fast. Ripgrep is faster. Both still scale linearly with the size of the code. If a coding agent’s job is to reason across not just one repository but its dependencies, and its dependencies’ dependencies, linear search becomes the bottleneck. Near-constant-time search is the only way to keep the lookup itself cheap enough that the agent can afford to ask.
The Trigrep variant goes further. The LST is built alongside the index, which means the trigram lookup can carry symbol information. An agent searching for “log4j info calls” doesn’t get every text match for “info(” followed by an open paren. It gets the call sites where the symbol is actually the log4j info method. That difference eliminates the grep-then-read-then-read-then-read pattern. The first query returns the answer.
The systems of record the agentic SDLC still needs
Moderne is preparing a set of capabilities, announced but not yet released publicly, that close the arc. Each is built on the same principle: the agentic SDLC needs new systems of record, not just new agents.
Changelog
Most organizations have more than one version control system. Even Moderne, at 65 people and 400 repositories, can’t easily answer the question “what did a given engineer ship today?” without crawling commit and PR history across every repo. Larger enterprises have the same problem at much larger scale, often across 10 or 15 different version control systems sitting in different network segments.
Changelog is the layer that sits on top of those systems and gives organizations a unified view of code activity (commits, PRs, merges) by contributor, by repository, by status. Made available through MCP, it gives coding agents the same view. An agent doing security review can ask “what changed in this service this week, by whom, with what review status” and get a real answer.
Transcripts
Transcripts is the system that watches the local MCP server, captures the agent’s session activity, and rolls it up against the organizational structure. The use cases named: knowing how many concurrent agent sessions an engineer runs, knowing where agents are struggling, knowing whether engineers are communicating their actual requirements to their agents or something adjacent.
The deeper purpose of Transcripts is identifying tool gaps. If a thousand agent sessions across an organization keep reaching for the same workaround, that’s a recipe that should be written. Transcripts is how the organization sees that pattern.
Artifacts
Modern software is roughly 80 percent open-source dependencies and 20 percent first-party glue code. A real transcript from Jonathan’s own machine shows a frontier coding agent trying to understand a binary dependency. Its strategy: create a temp folder, extract the binary, and read the bytecode.
That’s the current state. A frontier-scale model interfacing with the largest part of the software stack by reading machine instructions, because the artifact repository it’s pulling from is a file server with nothing else to offer. The next generation of artifact repositories will be different. Every binary pulled through will have an LST and a Trigrep index attached. The agent gets dense, symbol-aware access to its dependencies the moment it imports them.
From individual agents to an industrial park
The closing arc pulled back to the wider frame. If the toolset gets dense enough, if coding agents can be made accurate enough, fast enough, and cheap enough on token consumption, they stop being a tool used by individual developers and start being something else. Jonathan called it an industrial park.
Not one factory. Several. A factory that continuously upgrades and modernizes applications. A factory that continuously checks cloud readiness and cost optimization. A factory that continuously remediates vulnerabilities. Each factory taking inference as one input and a marketplace of thousands of recipes as another, and producing (as an industrial byproduct) new recipes that become inputs to the next generation of the same factory.
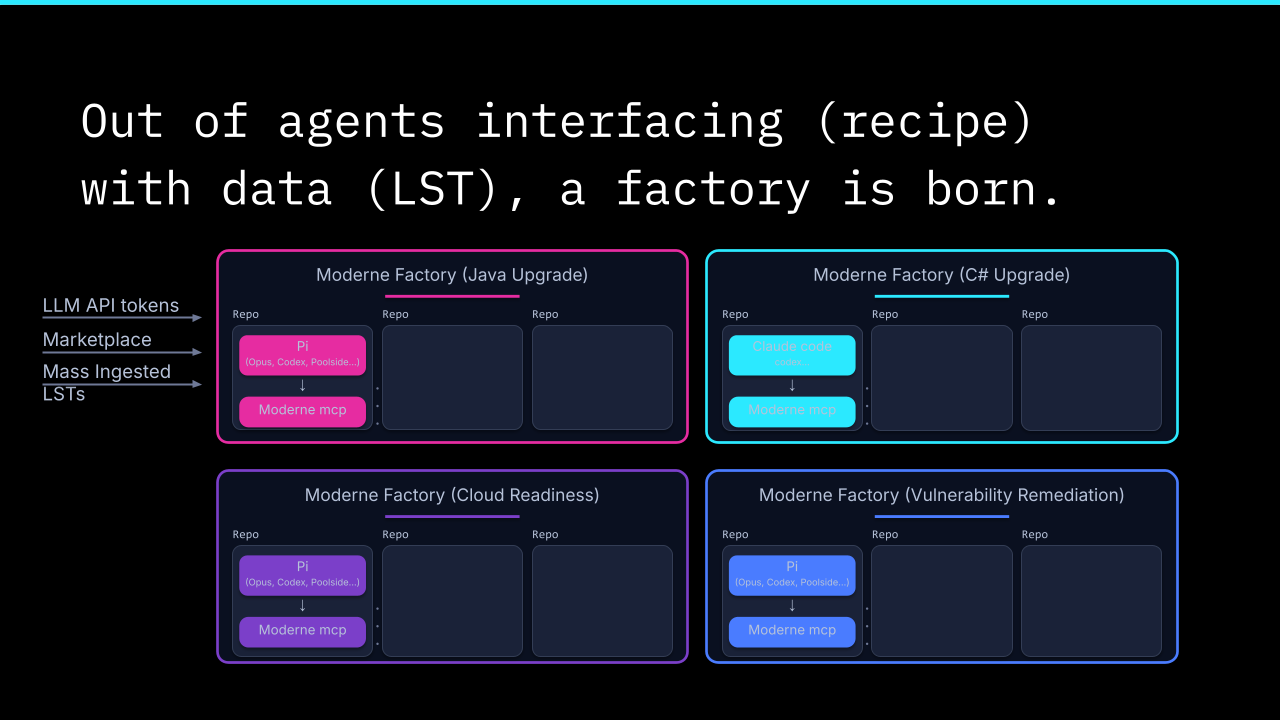
The goal of that industrial park isn’t to replace developers. It’s to shed the boring work. Migrations. Patches. CVE remediations. The kind of work that’s repetitive enough that it should be automatable, but complex enough that simple automation has never worked. The kind of work that, today, ties up engineering capacity that should be going to feature work.
We should be creating these factories in a whole industrial park. One for continuous upgrading or modernization. One to ensure cloud readiness. One to continuously remediate vulnerabilities. And that we’re building this industrial park that, to the greatest extent possible, sheds the boring work so that the humans are left still driving the interesting feature work.
Jonathan Schneider
The tools layer, built
The keynote’s argument was a category claim: the durable value in the agentic SDLC sits in the tools layer, not the model layer. The reason Jonathan could make that claim with live demos and benchmark numbers is that Moderne has been building the tools.
Trigrep for symbol-aware code search. Prethink for pre-computed context. Deterministic recipes for transformation. Changelog and Transcripts for coordination and governance. See how they work together: Moderne for AI Coding Agents.
Related posts


