Changing the AI context: How Moderne Prethink accelerates coding agents and reduces token use

Contents
- Don’t blame the agent. Blame the context.
- How Moderne Prethink works: Instant understanding, fewer tokens
- The foundation: Code as Lossless Semantic Trees (LSTs)
- Building a Prethink knowledge base
- Prethink output ready for AI
- AI coding agents using Prethink
- Agents always have the latest context
- Moderne Prethink: What agents need to know
- Semantic structure and patterns
- Service interfaces and integrations
- Dependency intelligence
- Security and configuration context
- Architectural and system relationships
- Testing insight
- Deployment context
- Customizing Prethink output
- Get the context coding agents can count on
The software development lifecycle is rapidly changing with AI—but not exactly as expected. Coding agents are now embedded in everyday workflows, and most organizations have spent the last six to twelve months experimenting with copilots and agent-driven development. The expectation was clear: faster delivery and higher productivity. The reality has been mixed.
A recent study by METR found that developers actually took 19% longer to complete tasks when using AI tools. They worked in large and mature repos, often more than a decade old and well over a million lines of code. In the study, developers consistently overestimated how much AI would help, then spent time correcting and rewriting generated code. Fewer than half of AI outputs were accepted as-is. AI needed the most help in large, complex repositories and failed to account for the implicit knowledge embedded in those codebases—architectural intent, conventions, dependencies, and historical decisions that aren’t visible from individual files or prompts.
Without reliable, semantic context, agents infer—and inference leads to rework, hesitation, and lost trust. If AI is going to deliver on its promise inside real-world codebases, improving the quality and structure of the context agents use isn’t optional. It’s foundational.
This is where Moderne’s experience becomes crucial. Long before AI agents entered the SDLC, Moderne was focused on helping humans work faster and more safely by improving code understanding. As the creators of OpenRewrite, we have built a multi-repo control plane that gives developers accurate, semantic insight into how code actually works at scale. Today, as agents take on more of the development workload, the same principle applies: better context leads to better outcomes.
Now, we’re introducing Moderne Prethink. With Prethink, that same deterministic code understanding is accessible as structured knowledge for coding agents, helping them work faster and more accurately.
Moderne Prethink is not MCP, RAG, embeddings, or prompt engineering. Prethink is compiler-accurate code knowledge with patterns, dependencies, connections, endpoints, configurations, and conventions already resolved. As a result, agents spend far less time inferring how code is structured or behaves, enabling faster, more reliable reasoning in the moment. No more burning tokens to reconstruct understanding. Agents now have a pre-resolved, auto-refreshed, fully customizable source of truth to rely on.
Get your first look at Moderne Prethink (and its token-busting value) here:
And read on to see how Moderne Prethink gives coding agents what they’ve been missing.
Don’t blame the agent. Blame the context.
AI models may falter today because “they can’t see all of my code,” “they burn through token budgets too quickly,” “they need to be checked all the time—inferring and hallucinating!” What a lot of this comes down to is not necessarily a fault of the model itself, but a data problem. When working with enterprise codebases, these models don’t have the necessary semantic context to be accurate and efficient.
Today, most agents operate on ad hoc, unstructured context, scoped by token limits, disconnected from any authoritative view of the code, and assembled differently every time. In that environment, inconsistent performance isn’t surprising.
AI coding agents rely on a combination of approaches to understand a repository:
Reading code directly—Agents scan files, follow references, and explore repository structure to build a working understanding of the code. This is a high-token approach that can be repeated across conversations, but ultimately only providing partial visibility.
Relying on documentation—Agents consult READMEs, wikis, and comments to infer design intent and usage patterns. Unfortunately, documentation and wikis are often outdated, incomplete, or disconnected from how the code actually behaves.
Retrieving context on demand—Agents use grep, embeddings, RAG, or MCP-style tools to pull in relevant snippets per query. Context takes time to build and still ends up being inferred rather than resolved, rebuilt on every interaction, and constrained by token limits.
Each of these methods forces the agent to do a lot of work to approximate understanding, leading to downstream effects:
**More tokens, more time—**When agents have to figure out how a repo works on the fly, they burn tokens and time reconstructing context. The answer may be right, but it often takes far longer than it should.
Fragmented understanding—Agents rarely see a coherent view of the repository. Instead, they work from stitched-together snippets, which increases inference, blind spots, and the risk of incorrect assumptions.
Context rot—As prompts, snippets, and retrieved artifacts accumulate over time, context becomes noisier and less relevant. Instead of improving performance, oversized or stale context actively degrades it.
Inconsistent outcomes—Without deterministic semantic inputs, agent results can vary between runs, require verification, and ultimately reduce developer trust.
There’s an important irony here. The institutional knowledge teams worry agents don’t have—architectural boundaries, dependency relationships, security conventions, and organizational standards—is already living in the codebase itself. It’s encoded in structure, configuration, dependencies, and patterns. The problem isn’t that this knowledge is missing; it’s that agents don’t have a way to see and use it.
**The O’Reilly report on Automated Code Remediation at Scale covers why AI needs structured code data to work at enterprise scale and what that looks like in practice. **Download the eBook →
How Moderne Prethink works: Instant understanding, fewer tokens
Moderne Prethink remakes “context” for coding agents. With Prethink, context is no longer a collection of prompts and snippets for assembling understanding—it’s resolved, semantic knowledge derived directly from the code. This knowledge is versioned like code, refreshed as code changes, and consulted by AI agents at development time.
This shifts agent behavior in a fundamental way: agents stop reconstructing the repository every time they’re asked a question and instead reason from a shared, authoritative understanding of the code in scope. The result is faster reasoning, lower token usage, and more consistent outcomes.
Let’s review how Prethink works:
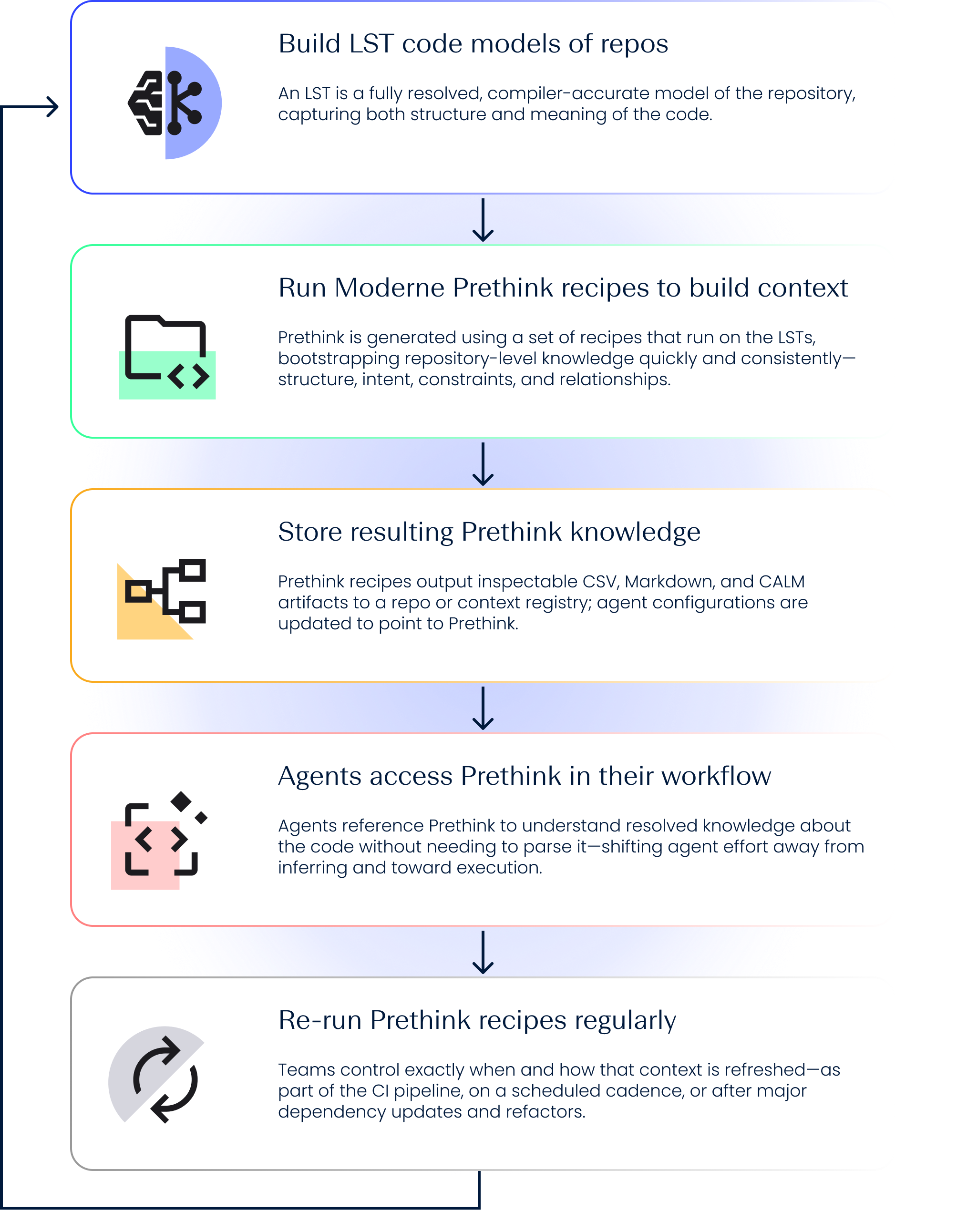
_Want to see Prethink working in a real codebase live? _Watch the on-demand demo →
The foundation: Code as Lossless Semantic Trees (LSTs)
Prethink is leveraging a different baseline than other AI tooling. It’s derived from Moderne’s Lossless Semantic Tree (LST)—a full-fidelity model that has powered deterministic transformation in OpenRewrite for years. The LST captures both structure and meaning, reflecting what the code actually represents.
This is not an AST, and it is not an embedding. It is a fully resolved, compiler-accurate model of the repository. The LST is:
Lossless—No loss of actionable context for agents, including full type attribution, code intent, and comments—nothing discarded.
Semantic—Every symbol, type, method call, configuration reference, and dependency is resolved to what it actually refers to.
Tree-based—Structured and navigable for search, extraction, and transformation with recipes—not a blob of text.
This level of semantic resolution is what makes it possible to build context that agents can trust and reuse.
Building a Prethink knowledge base
Prethink is generated using a set of recipes that run on the LSTs, bootstrapping repository-level knowledge quickly and consistently. Moderne provides two starter recipes, but these are fully customizable by customers.
The two Prethink starter recipes from Moderne include:
io.moderne.prethink.UpdatePrethinkContextNoAiStarter: Builds a comprehensive Prethink knowledge base using deterministic analysis alone, exporting structured data on dependencies (including transitive trees), test coverage, and related signals, and generating a CALM-formatted architecture diagram. Ideal for teams that want strong semantic grounding without AI-generated summaries.
io.moderne.prethink.UpdatePrethinkContextStarter: Includes everything above, and additionally uses AI (via BYOM) to generate a knowledge graph from the extracted semantic data and to produce summaries of tests and coverage.
An important final step with both recipes is that they automatically update the AI agent configuration files so agents know how to reference Prethink automatically in their day to day work. The starters can also be customized to push Prethink data elsewhere, such as to a context service.
Prethink output ready for AI
The generated Prethink artifacts are materialized in inspectable formats as part of the knowledge base—such as Markdown, CSV, and CALM models. They are committed directly to the repository, versioned and reviewable.
| Files | What it contains | Examples |
|---|---|---|
| CSV files (data tables) | Structured data that AI agents can parse and query directly; used to generate CALM JSON | service-endpoints.csv database-connections.csv dependencies.csv |
| Markdown files | Context and schema information readable by humans and agents | service-endpoints.md database-connections.md dependencies.md |
| CALM architecture JSON file | Architecture diagram visualized using CALM-compatible tools | calm-architecture.json |
| Updated agent configuration | Enables progressive discovery so agents learn about context first, then read relevant files as needed. | CLAUDE.md .cursorrules .github/copilot-instructions.md |
AI coding agents using Prethink
AI agents are configured to consult Prethink as the primary source of repository context during their normal workflow, helping them understand the codebase and get right to the task at hand. Agents can:
Access resolved knowledge about the codebase without needing to parse it
Understand schema and meaning of data without additional prompting
Use a knowledge graph built with BYOM (if available)
Use CALM formatted architecture information
This shifts agent effort away from interpretation and toward execution—reducing guesswork, token usage, and variability across sessions. Every agent working in the repo can leverage the same Prethink knowledge base.
Agents always have the latest context
Because Prethink is derived directly from the code, agents can work from context that reflects the latest state of the repository. Teams control exactly when and how that context is refreshed—whether as part of the CI pipeline, on a scheduled cadence, or after major dependency updates and refactors. Teams can also fully customize the context that’s generated for their organizations. This way agents can always reason from current, trusted, targeted knowledge without manual curation.
Moderne Prethink: What agents need to know
For coding agents to be effective inside real-world repositories, they need the same kinds of knowledge experienced developers rely on—structure, intent, constraints, and relationships—made explicit and easily consumable by agents. Prethink is designed around this principle, giving agents the knowledge they need to reason faster and more consistently, without forcing them to infer or reconstruct it.
Semantic structure and patterns
Agents need to understand not just what code exists, but how it is used in practice. This includes how the codebase is organized, which patterns recur, and how conventions are applied over time—such as error-handling approaches, dependency-usage norms, and idiomatic structures that aren’t obvious from individual files.
Service interfaces and integrations
Modern systems are defined by how they interact. Prethink exposes resolved service endpoints, database connections, external service calls, and messaging patterns so agents can reason about impact, integration boundaries, and downstream effects with confidence.
Dependency intelligence
Dependencies shape behavior, risk, and upgrade paths. Prethink provides complete dependency trees—including transitive dependencies—along with version relationships, giving agents visibility into impact, compatibility, and risk without relying on incomplete scans.
Security and configuration context
Much of a system’s behavior is governed by configuration rather than code alone. Prethink surfaces security-related configuration, such as framework-level authentication setup and access controls, so agents can see how security is configured without inferring it from scattered files.
Architectural and system relationships
Beyond individual files or services, agents need to see how components fit together. Prethink provides CALM-formatted architectural artifacts and component relationships that describe system structure explicitly, with optional AI enrichment for higher-level summaries. CALM (aka Common Architecture Language Model) was defined in FINOs as a model humans and machines can understand to help ensure architectural decisions are consistently applied and easily auditable.
Testing insight
Agents need to understand how code is validated, not just how it’s written. Prethink includes test coverage, test-to-implementation method mappings, and coverage analysis at the endpoint or method level. Where desired, teams can optionally enrich this with AI-generated summaries via BYOM to help agents reason about test intent and gaps.
Deployment context
What runs in production is shaped by how it’s deployed. Prethink connects deployment artifacts—such as Docker and Kubernetes configurations—back to the code they affect, allowing agents to understand deployment constraints and operational considerations when evaluating change.
_Ready to go deeper? _Explore the Prethink documentation →
Customizing Prethink output
Crucially, Prethink is customizable by design because its knowledge is generated programmatically with Moderne recipes. Teams decide what context matters most for their agents, such as architectural boundaries, dependency usage, security considerations, conventions, migration goals, or all of the above.
That knowledge lives with the code, evolves as the code evolves, and ensures that agents reason from the same understanding the organization expects—without relying on ad hoc prompts or tribal knowledge. This also prevents overloading agents with irrelevant data and eliminates the need for brittle prompt engineering. The result is right-sized, high-signal context that improves accuracy, consistency, and token efficiency.
_Join us to see how teams are customizing Prethink for their own codebases. _Save your spot →
Get the context coding agents can count on
When agents have access to Moderne Prethink, they don’t need to guess how a repository works or what’s allowed. They can reason from facts, align with team intent, and focus on getting work done.
Prethink ensures:
Agents have deeper knowledge locally
Agents can get to the answer faster
Token budgets shift from understanding to execution
More consistent outcomes across developers and sessions
Teams can customize the knowledge
Related posts


