Modernizing off of legacy Java app servers: deconstructing to automate

Contents
A security team at a major bank flagged a vulnerable dependency. The fix required Java 17, but Java 17 couldn’t be adopted because 3,000 apps ran on WebSphere Traditional, which required Java 8. Those apps were also tied into WebSphere MQ, so getting off the app server meant unwinding part of the integration layer too. A one-line dependency bump became a multi-year stack migration.
If you’ve ever read If You Give a Mouse a Cookie, you know how this goes. He asks for a glass of milk, then a straw, then a napkin, and before long you’re not sure how you got where you ended up. App server modernization works the same way, except the mouse is your CFO and the cookie is a CVE.
This is the part of modernization people don’t really want to talk about. Most conversations start with the destination: cloud-native, microservices, Spring Boot, Kubernetes. A better conversation starts somewhere humbler. Not “where do we want to end up,” but “what’s the next move we can actually finish?” Break the journey into pieces small enough to ship before the next re-org or budget cycle disrupts them, get one of those pieces done, and use what you learn to size the next one.
Coding agents are the newest reason teams think they can skip this foundation work. Agents can make it easier to produce changes, but they aren’t guaranteed to be the right ones, and they don’t make the work coordinated by default. Point an agent at a WebSphere migration and you might get plausible-looking PRs that don’t add up to a finished migration. Run that across three thousand repos and watch your token budget evaporate.
No matter who or what makes the changes, you have to manage scope, sequencing, review, and consistency. That coordination problem starts with the lock-in itself.
The lock-in has a predictable shape
Whatever app server you’re on, the trap looks roughly the same:
Proprietary APIs that don’t have JEE-standard equivalents, so your application code calls a vendor namespace directly.
Descriptor sprawl with vendor-specific XML files that the build pipeline requires.
Integration-layer entanglement where messaging, transactions, or resource management depend on vendor-specific runtime behavior.
EJB dependencies where session beans, container-managed transactions, or timer services are in use.
WebSphere, WebLogic, and JBoss EAP are the canonical examples, though the same pattern exists wherever an app server has accumulated proprietary surface area. Regardless of the specific vendor namespace, it’s the same trap.
The painful part is that these layers don’t move independently. You try to upgrade Java and discover the app server won’t support it. You try to change the app server and find application code calling vendor APIs directly. You try to remove those APIs and end up in deployment descriptors, resource adapters, and runtime configuration.
That’s the “mouse asking for a glass of milk” moment. One reasonable fix reveals the next prerequisite, then the next, and each one has to be sequenced across the estate.
Horizontal changes keep the estate aligned
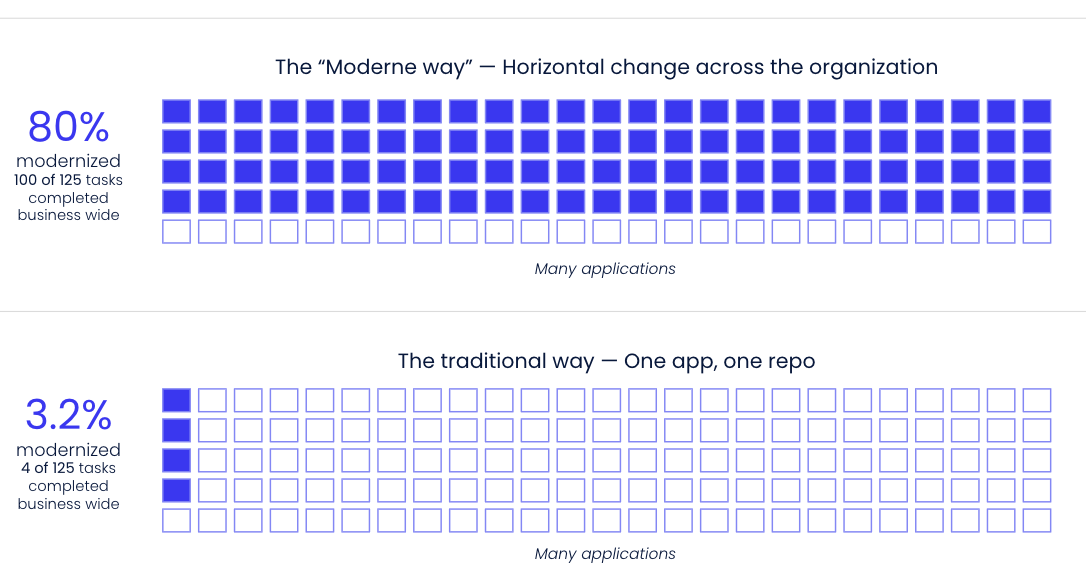
Lock-in explains why one app is hard to move, but volume is why the program stalls.
Three thousand apps is not a portfolio you can migrate one at a time. A repo might be a deployable application, a shared library, or the place where deployment configuration lives for an app whose business logic is somewhere else. And even if you get a few hundred in, the organization has usually changed around the migration by then: teams reorganize, priorities shift, budgets move. The apps already migrated still need support on the new target while the rest of the estate remains tied to the old one, and now you’re running two operating models instead of one.
The answer isn’t more capacity. Most enterprises have already gotten a consultancy quote for this work, and the number tends to be its own argument for not starting. Whether your engineers do the work, a consultancy does, or an agent opens the first pass of PRs, each application still needs discovery, migration, testing, review, and coordination. More people can move more apps in parallel, but if every app moves as its own vertical project, the program is still paying the same tax over and over.
The alternative is horizontal: instead of “modernize this app,” the question becomes “remove WebSphere MQ from every repo that uses it” or “migrate every javax namespace reference to jakarta across the org.” It’s a narrower question with a much bigger surface, and the answer is the same everywhere. Centralizing the pass also removes the dual-mode problem. When teams define the destination independently, you end up running multiple messaging stacks or multiple runtimes, which compounds the problem rather than solving it.
With the Moderne Platform, OpenRewrite recipes automate code transformation, running the same way across every repo in scope and verified deterministically. The goal is to handle at least 80% of the migrations across the board. Some repos will sail through cleanly, some won’t. There are always wonky setups, half-converted projects, and repos whose original owners have left. Automating the 80% collapses the straightforward cases so engineering time can go to the cases that actually require thought.
Why direct jumps to cloud-native usually fail
Spring Boot, Kubernetes, and microservices may be the right destination eventually. The mistake is treating them like the next step.
A direct jump fails because the foundation problems do not disappear when the target gets more ambitious. The proprietary APIs are still there and the Java version is still pinned. Moving straight to Spring Boot or Kubernetes means solving all of that while also changing the application model, deployment model, and operational model.
That is how a modernization program gets too big to sequence. What started as “get off WebSphere” becomes “change how the app starts, packages, configures, deploys, observes, and operates.” Each change might be reasonable on its own, but bundled together across a large estate, the work becomes harder to automate, harder to review, and harder to finish.
The better move is to separate the platform exit from the cloud-native destination first: get off the legacy runtime, reduce the proprietary surface area, and unpin the Java version. This creates a cleaner foundation so you can then decide what the next move is. It’s easier to consider Spring Boot, Kubernetes, Quarkus, or a rewrite when you start from there. Or maybe leaving the app on a smaller runtime is good enough as it is.
Deconstructing your WebSphere challenge first
Deconstruction comes before migration. There are three calls to make before you write or run a single recipe.
Pick a horizontally feasible target, not an ideal one. WebSphere Traditional to Open Liberty if you want to stay close to IBM. WebSphere or WebLogic to Tomcat for teams already planning containerization. JBoss EAP to Jetty when the goal is a lighter footprint with the same servlet-container model.
The target is still an app server and the deployment model stays the same. The apps still package as WARs and get deployed to a runtime, but the proprietary surface area shrinks.
This work is more about getting off the legacy platform than about modernizing. That’s a feature, though, not just a hedge. Modernization is what becomes possible once the foundation can support it.
Pick the prerequisites and decide how to sequence them. The app server may be the thing you want to leave, but it is not always the first thing you can move.
For example, if your apps use WebSphere MQ (as in the bank example), the path off WebSphere means moving the messaging layer first, whether to RabbitMQ, Kafka, or another platform, before you touch the app server. In other scenarios the blocker might be transaction management, resource adapters, connection pooling, or some other runtime service the application assumes the app server will provide. More likely you’ll be contending with multiple app server-specific dependencies.
That’s why the sequence matters. You can fold the prerequisite work into the same recipe pass, which is faster, or pull it out as a separate step, which may be safer. The right answer depends on how much regression risk your team is comfortable with in one cycle.
Do one repo manually, but don’t generalize from one repo. This is the step where vertical thinking sneaks back in. A team picks a representative repo, does the migration by hand, watches it work, and assumes the changes will be the same everywhere. In the next set of repos, the assumption falls apart because vertical migration is the wrong default at the portfolio level; it’s also the wrong default at the recipe-development level.
The point of the manual pass is to learn what the migration actually involves before you start encoding it. Repos aren’t standardized, which is the whole reason this work is hard, so pretending otherwise just defers the discovery. Start with doing one by hand, which will inform recipe creation, but then dry-run the in-progress recipe across the whole pilot set (or the whole org) and let the gaps and edge cases surface.
You’ll find, almost immediately, that “this is a JBoss project” is harder to assert than it sounded in the planning meeting. JBoss-specific files might live in one repo while the business logic that gets packaged into that JBoss deployment lives in another. You’ll find a standalone.xml file sitting in an openshift/ folder that nobody documented. The manual pass plus the broad dry run is where the gotchas surface.
Where coding agents fit for legacy app server migration
The methodology doesn’t change because coding agents exist now. What changes is how much of it an agent can carry.
A recipe is deterministic: the same input leads to the same change every time, so it’s auditable across thousands of repos. An agent making a fresh judgment call per repo is the opposite, and at three thousand repos that’s not auditable and not safe. But agents definitely have a place here:
They can write recipes. Once it’s clear what the migration actually involves, an agent can draft recipes, working from the existing catalog as a pattern, and from your codebase as the target.
They can run recipes. An agent orchestrating a recipe run across the estate is still deterministic, because the recipe does the transforming and the agent does the driving.
They can go the last mile. When there are trickier repos where no recipe fits cleanly, an agent committing cleanup with help from context surfaced by Moderne, definitely beats a human doing it by hand. And it can write recipes here too if it makes sense, to keep things deterministic.
What agents should not do is remake the entire transformation itself, repo by repo, with no recipe underneath. That defeats the purpose of the horizontal pass in the first place.
The thread running through all of this is grounding: the agent works from the same semantic representation the recipes use, not a guess about what your code looks like. It’s how agents can do credible work on this kind of migration. (We’ve written about drafting recipes with AI, and there’s a hands-on workshop that walks through it with the Moderne CLI’s AI skills.)
Five steps in practice
The methodology distills into five steps:
Collect the set of repos in scope. This sounds trivial, but it often isn’t. Some repos might contain a JBoss-specific file that lives in one repo while the deployment that uses it lives in another. And repos aren’t always microservices either. Knowing what you’re looking at usually means scanning the whole codebase rather than trusting the repo names. Moderne’s search recipes are a practical starting point here: run a finder recipe to identify every repo that references a vendor namespace, declares a specific dependency, or ships a given descriptor, and let the results define your scope rather than a spreadsheet someone maintained by hand.
Decide your destination and establish a baseline. Define the target so the work has a shape, then normalize the portfolio toward a consistent starting point: Tomcat, Jetty, Open Liberty, or something else. Moderne DevCenter lets you track both the baseline view of where every repo sits today, and the target state you’re moving toward. A baseline composite recipe like Maven best practices or Common static analysis levels the terrain so the harder migration that follows has fewer hidden sources of drift between repos.

Run a dry-run assessment to surface blockers. Select or build a draft migration recipe and dry-run it across the whole org. You can even pair it with the Verify compilation recipe to flag what breaks. Then use code insight recipes like Find types, Dependency insight, or Plan a Java version migration to quantify hotspots:
javax.*usage, vendor-API call sites, code generators, etc. The dry run plus code insight tells you what your real blockers are _before _you commit to a transformation, not after. It’s also worth establishing a test baseline at this point. Compilation passing and tests passing are different bars, and knowing which repos have meaningful test coverage before you start will shape how you sequence the work and what the review bar looks like in each wave.Build and run recipes against a handful of repos. Start with one repo, verify the result, then encode the transformation as a recipe and run it against a few more to spot-check before dry-running again against the broader set. The OpenRewrite catalog already covers a lot of the moving parts, so composite recipes can often handle the bulk of the descriptor-level work. The catalog offers existing recipes to Migrate from WebSphere to Liberty, or Migrate JBoss to Tomcat, or Migrate to Jakarta EE 9. There are also XML recipe primitives (Change tag attribute, Change tag value, Add or update child tag) you can use as the building blocks for custom descriptor work to change a vendor-specific element in files like
standalone.xmlorweblogic-ejb-jar.xml.Scale in waves and accept the 80/20 reality. Run the recipe against the full set, but not as a single big-bang operation. You’ll need to sequence the migration based on internal dependencies and complexity. Moderne’s Release Metro Plan recipe generates a dependency-based wave map from your Maven or Gradle project graph: repos with no internal dependencies go first, downstream repos follow once their upstream libraries are upgraded and released. Each wave follows the same rhythm: run the recipe, review the diffs, commit what fits, release. Some repos will sail through and some will need a few manual commits. You may find some apps that were going to be retired anyway, but now you finally have the visibility to know that. What’s left after this work is a cleanup effort you can more easily scope, assign, and finish. The wave plan gets you to a validated, migrated state in your pipeline. Production cutover (blue/green, canary, or feature flag) is the step that follows, and it’s a lot less stressful when the migration work is already behind you.

One step closer across the estate
The point of all of this is to get somewhere from where you are today, and “somewhere” is more modest than most modernization programs admit. You want to reduce the proprietary surface, unpin the runtime, and clean up legacy descriptor sprawl. Then the next decision (Spring Boot, Quarkus, containerize, rewrite, or just stay on Tomcat) is finally one you actually get to make, rather than one that’s been made for you by what the estate happens to be tied to.
The same horizontal-first approach applies to your pending database migration, a message broker consolidation, and the framework upgrade that’s coming. The infrastructure you build to do this once works on more than one problem, and so does the muscle. And this methodology doesn’t care who’s at the keyboard: humans, agents, or some mix, with the same deterministic foundation underneath either way.
Platform migration
See it on your own estate
Moderne runs deterministic recipes across every repo at once, dry-runs the migration before you commit a single change, and maps the dependency-based wave plan for your codebase. Bring your WebSphere, WebLogic, or JBoss estate and we will walk through what the first pass looks like.
Related posts


