AI code search at scale: Finding method invocations with natural language
Contents
Before starting any migration or major refactoring work, it’s common for developers to do research to understand the scope of the change. Searching the code can be a hit or miss, though, because the query is based on what a developer thinks they know about the code (which can miss a world of instances). You think you know your code until you try to find everywhere you use an authorization header, like in the case of one of our customers.
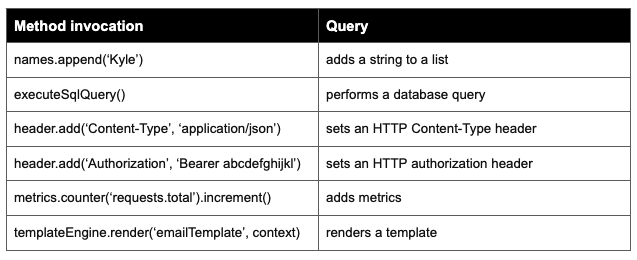
We were helping a customer build a migration recipe to move from one identity and access management (IAM) provider to another. The first step of this was to search all applications for a particular HTTP header. Inside the organization’s codebase, multiple Java libraries were in use for the basic use case of making a microservice-to-microservice HTTP call, such as Spring’s WebClient, OkHttp3, and Spring’s HttpHeaders. We needed to identify applications of that header regardless of the Java library used to make the HTTP call.
This was easy enough to do with the OpenRewrite catalog of recipes, such as “Find method usages,” providing we knew the library and method name to insert. The customer could think of two libraries initially but later realized they had missed a third.
This got us thinking. Wouldn’t it be useful to have a recipe that searches all the repos for the different methods that do an action using AI natural language search? This could provide powerful impact analyses that don’t require developers to know all the code structure and relationships, which are not always straightforward or well documented.
For those who like to read the end of the book first, check out our video that demonstrates the final recipe we developed.
Read on to learn about our process of creating the recipe, which was done in collaboration with Mila - Quebec Artificial Intelligence Institute under the Scientist in Residence program.
Searching code accurately and at scale with AI
We needed an AI-powered recipe that would be quick using self-hosted models and able to find a maximum of relevant instances.
Given the need to scale the search process across large repositories, we quickly realized that brute force methods wouldn’t be practical. The sheer volume of method invocations would result in an unmanageable amount of processing time. For instance, if we had a codebase of 1218 repositories that contains about 365K method invocations (such as the open source repos in Figure 1), and we used a fairly quick model that can process 10 searches in 1 second, it would take roughly 10 hours for a single search. This is far from efficient, especially when dealing with time-sensitive projects.
To tackle this challenge of large-scale search space, we turned to a technique known as top-k selection. The idea here is simple: instead of evaluating every single method invocation, we focus on the most relevant ones. By gathering all method signatures and prioritizing the top-k—where k is a sizable number like 5 or 10—we can significantly reduce the time spent on the search without sacrificing too much accuracy. So we built a two-phase pipeline, shown in Figure 2, for this search functionality. The first phase reduces the search space, and the second phase actually does the search.
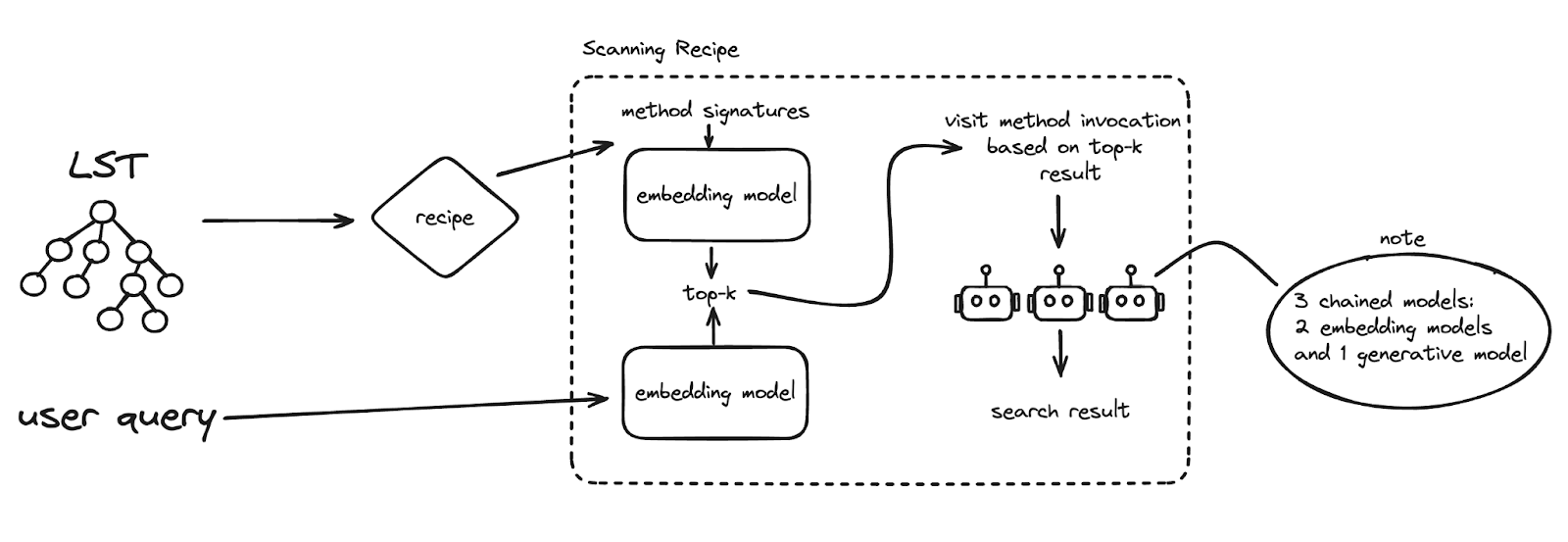
Here’s how our pipeline works:
Method signature accumulation: Using a scanning recipe from the OpenRewrite framework, we visit all method invocations and collect their signatures. During this process, we also deduplicate the signatures to avoid redundant checks.
Prioritization: We then prioritize these signatures based on their similarity to the user’s query. This is done by comparing the embeddings of the method signatures with the embedding of the query. The closer the embeddings are, the higher the priority. We use pure distance as our metric, though this can vary depending on how the embedding model is trained. Once we have our prioritized list, we revisit the code, but this time, we only examine files that contain one of the top-k methods. This selective approach allows us to narrow down the search drastically.
Model chaining: To ensure accuracy, we employ a series of models in a chain. We start with a smaller, faster model and progressively move to larger models only if the initial models can’t confidently determine a match. The final model in the chain is a generative model that predicts whether two items are related based on the probability that the next generated word is “yes.”
We will look at all of these in the following sections.
Method signature accumulation
To implement the search space reduction using a top-k method, we use a scanning recipe. A scanning recipe is a type of recipe in OpenRewrite that extends the usual recipe by adding an accumulator to store information and a scanner to populate this data. It works in three phases: scanning to collect data without making code changes, optionally generating new files, and finally editing code based on the accumulated data. This permits us to grab all the method signatures for all the methods in use in a repository.
Prioritization
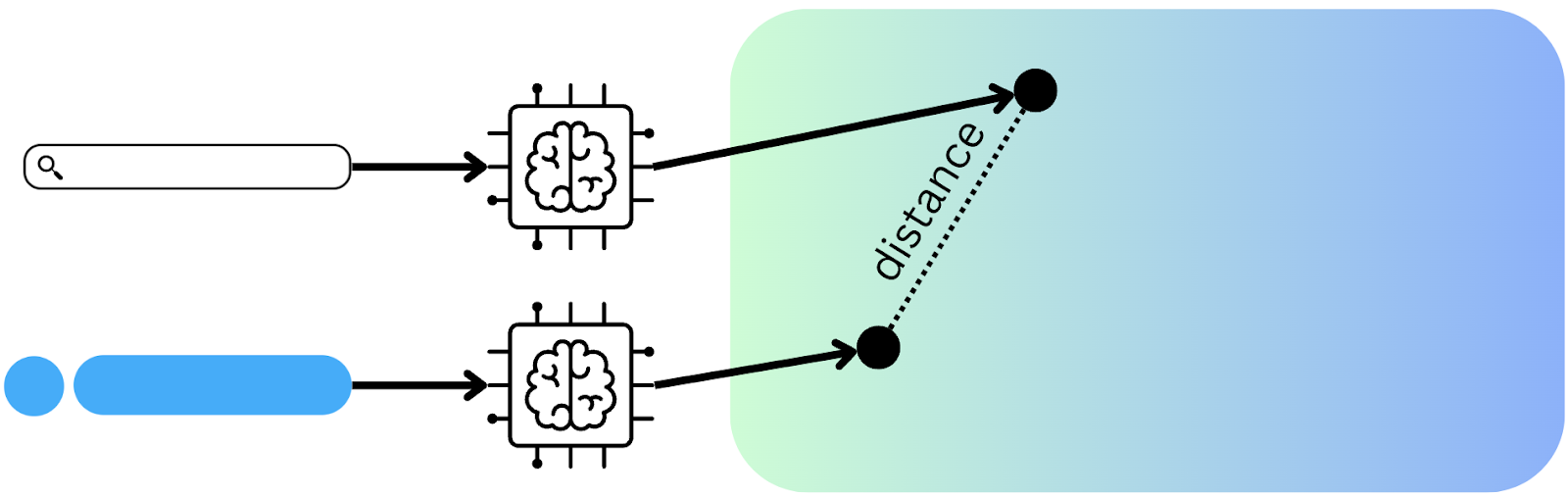
We use an embedding model from Beijing Academy of Artificial Intelligence called BAAI/bge-small-en-v1.5, a model that performs well on the MTEB leaderboard. We get an embedding for both the query and the method pattern, and get the distance between the two. Using this distance, we can then have an ordering that tells us which method to prioritize in search. Depending on the k provided by the user, we only search through method invocations that use one of the top-k method patterns.
Model chaining
After the scanning part of the recipe is finished, we can then go visit every method invocations that match one of the top-k methods. To then determine if that method invocations does what the user provided query says, we utilize up to three models. Why up to three? Chaining three models, from smallest to largest, enables the first, faster model to answer the easier questions. And only if that question is too difficult, then we go to the second model, and so forth. The reason why we weed out the easier questions is because the larger a model is, the “smarter” it tends to be. Unfortunately, this also means it’s slower.
To be precise, we used SmartCompenents/bge-micro-v2 as our smaller model, which is a two-step distilled version of BAAI/bge-small-en-v1.5. The medium sized model is BAAI/bge-large-en-v1.5. And finally, the larger model is CodeLlama (7b).
Choosing the most efficient, effective AI model combos
So the two first models work by embedding the query and the method invocation, which means mapping the text to a vector representation. Since we then have a vector representation, we can compute their distance using cosine similarity. So, how can you figure out a threshold for which the method invocation’s embedding is too far (or not too far) from the query’s embedding?
You could find that threshold one model at a time, but we are also interested in optimizing the speed while keeping the accuracy high, so you need to find the thresholds for the pair of models together. You could test each possible pair of models out on a bunch of queries and time it, but that’s a very long and boring repetitive process.
Here’s what we did instead to choose the most efficient and effective model combination:
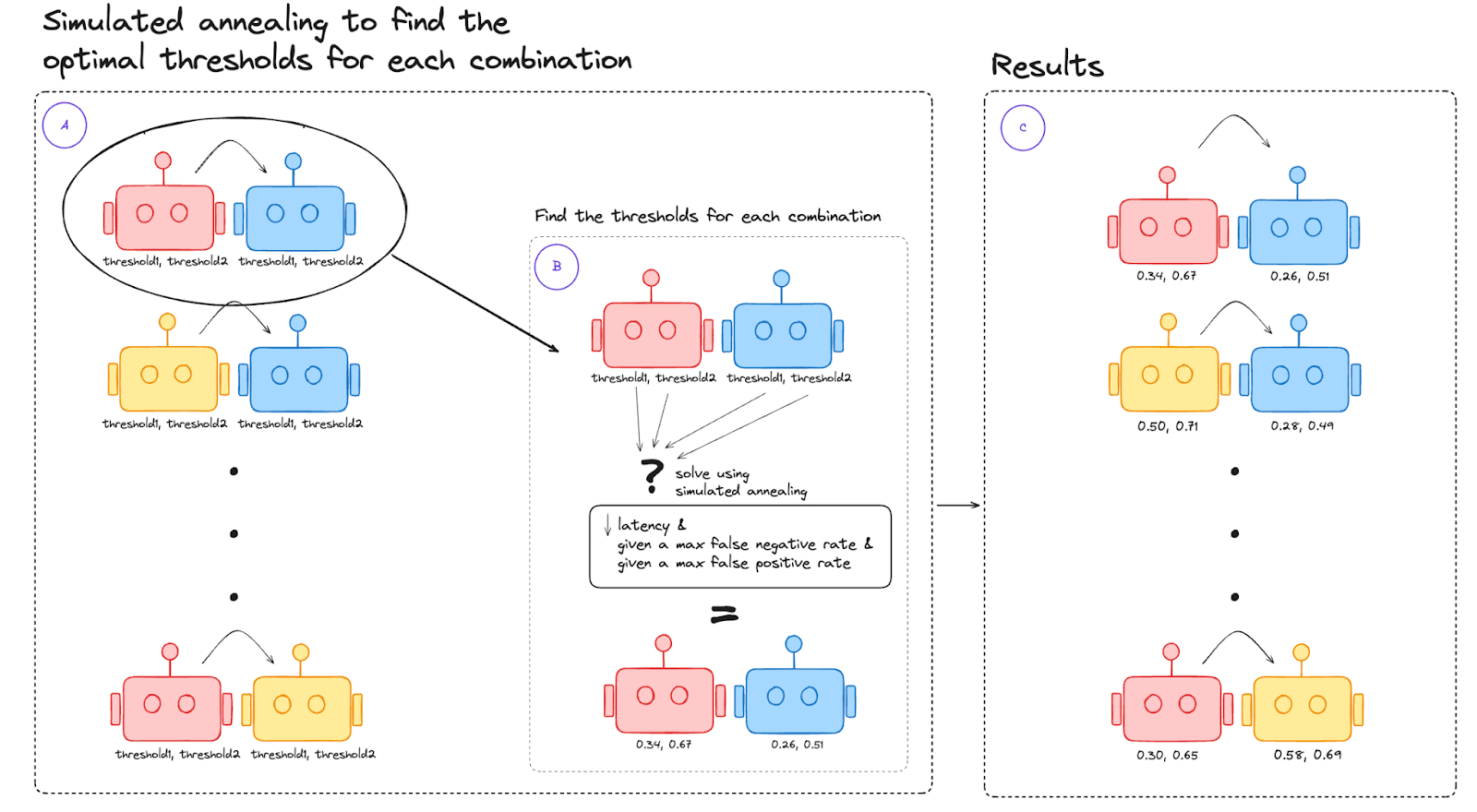
We pair up all the models (all the possible combinations), as seen in Figure 3.
For each combination, we find the thresholds using simulated annealing (which we explain below).
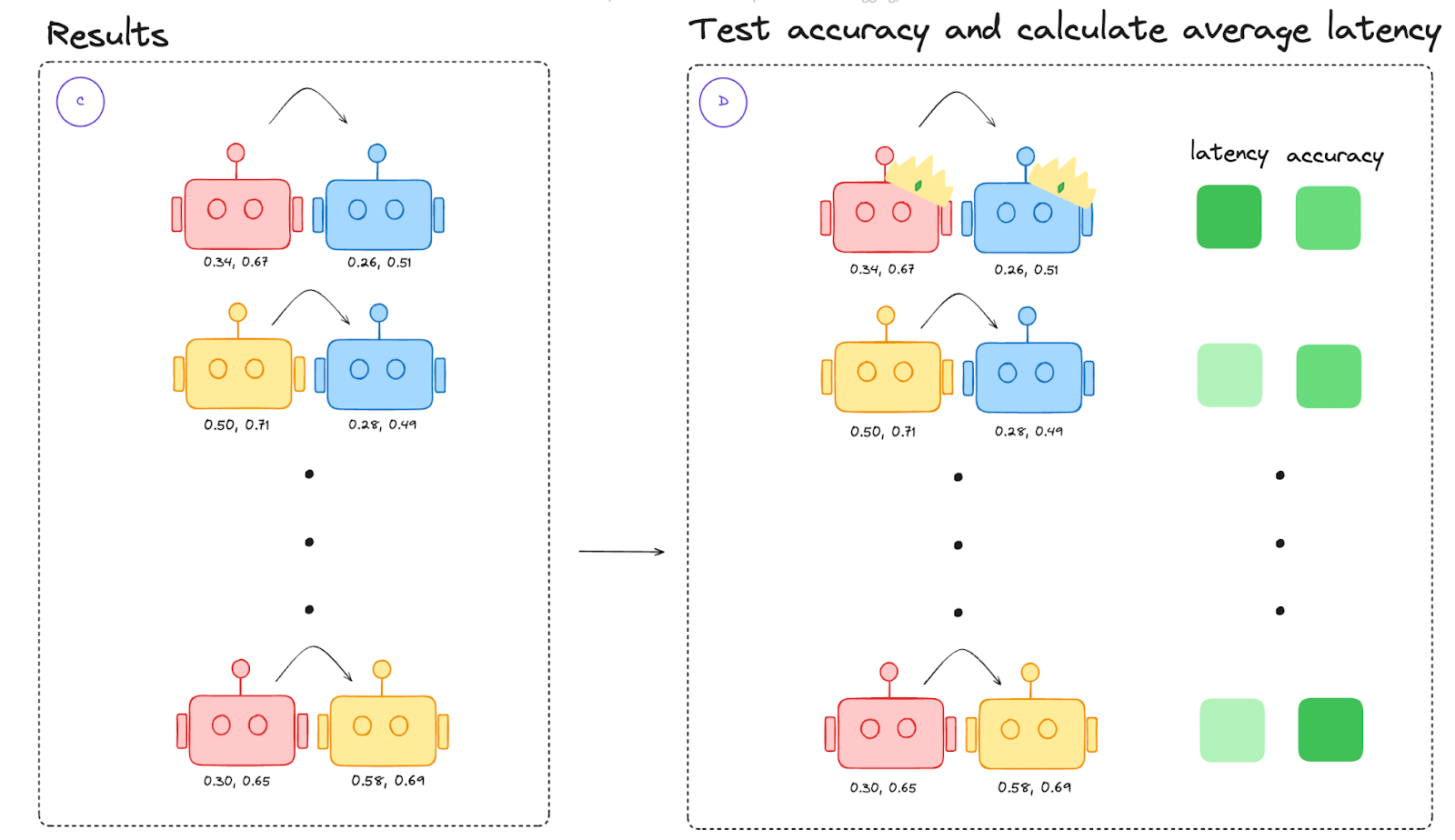
We test the set, where we try the results from B, looking both at accuracy and latency, then choose one that does well on both fronts as shown in Figure 5.
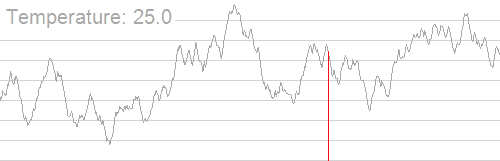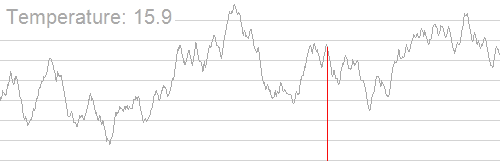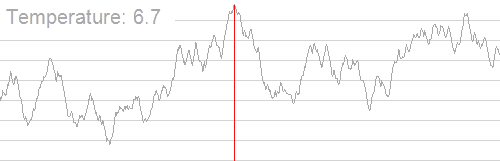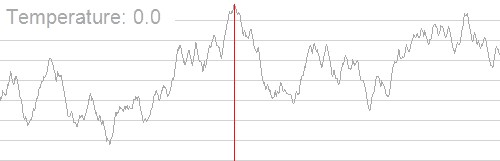
Simulated annealing is an optimization technique inspired by the process of annealing in metallurgy, where a material is heated and then slowly cooled to reduce defects. It finds an approximate global optimum by exploring the solution space, occasionally accepting worse solutions to escape local optima (either the minimum or maximum within a small range of nearby possible solution sets), with the probability of accepting worse solutions decreasing over time.
If we take Figure 4 as an example, you can imagine the 2D plane as a landscape with hills and valleys, where the algorithm’s goal is to find the highest peak (the highest point on the y-axis). Simulated annealing works by starting at a random point on the landscape and exploring nearby areas to see if they are higher. At first, the algorithm is willing to move to both higher and lower points (even going down a bit into valleys) to avoid getting stuck on smaller hills. As the process continues, it becomes more selective, favoring moves that go uphill, until it eventually focuses on finding the highest peak on the landscape. Here, the temperature controls how much the algorithm is willing to explore lower points. At a high temperature, it freely moves around the landscape, but as the temperature decreases, it becomes more focused on moving uphill to find the highest peak.
Now, back to our problem. You can imagine the y axis being the latency, and we want to find the set of thresholds for each model that minimizes the latency. While there are more dimensions in the solution space, the algorithm works the same way.
We automatically optimize the thresholds for speed, given a max false positive rate between 0 and 1 and a budget of false negatives between 0 and 1. For example, if the false positive rate is 0.10 and the false negative rate is 0.05, the model will incorrectly flag more instances than it will miss. So, why is the false positive rate different from the false negative rate? We want to choose a threshold such that the queries that are ambiguous do get accepted as a search result, since this is a discovery problem after all. We would rather accept a couple search results that we probably shouldn’t have than to miss some hits.
One of the interesting things about this solution space is that, if the first model always defers to the second model, the latency is going to be very long since the second model is larger than the first. There is a fine balance between a first model that takes all the decisions, and one that takes none. We want the first model to make some decisions, and only defer the tougher ones to the slower but smarter models.
We have a dataset of method invocations and matching queries that we handwrite. Having a test set is essential to see if setting the thresholds actually works.
Testing the models together with their optimal thresholds. We look at both their average latency and their accuracy on the handwritten test set as shown in Figure 5.
While we tested multiple models from BAAI (various size, quantization-levels, reranker or distance-based) as well as SPADE (which is open-source but not available for commercial use), we found using SmartCompenents/bge-micro-v2 as our smaller model, followed by BAAI/bge-large-en-v1.5, and with finally codellama(7b).
We found that having the Code Llama model in the third position was a great final decider. Having a generative model that can understand a little better the intricacies of a query than a mere embedding model worked best as the final fail safe on the pipeline.
Running the ‘Find method invocations’ recipe powered by AI
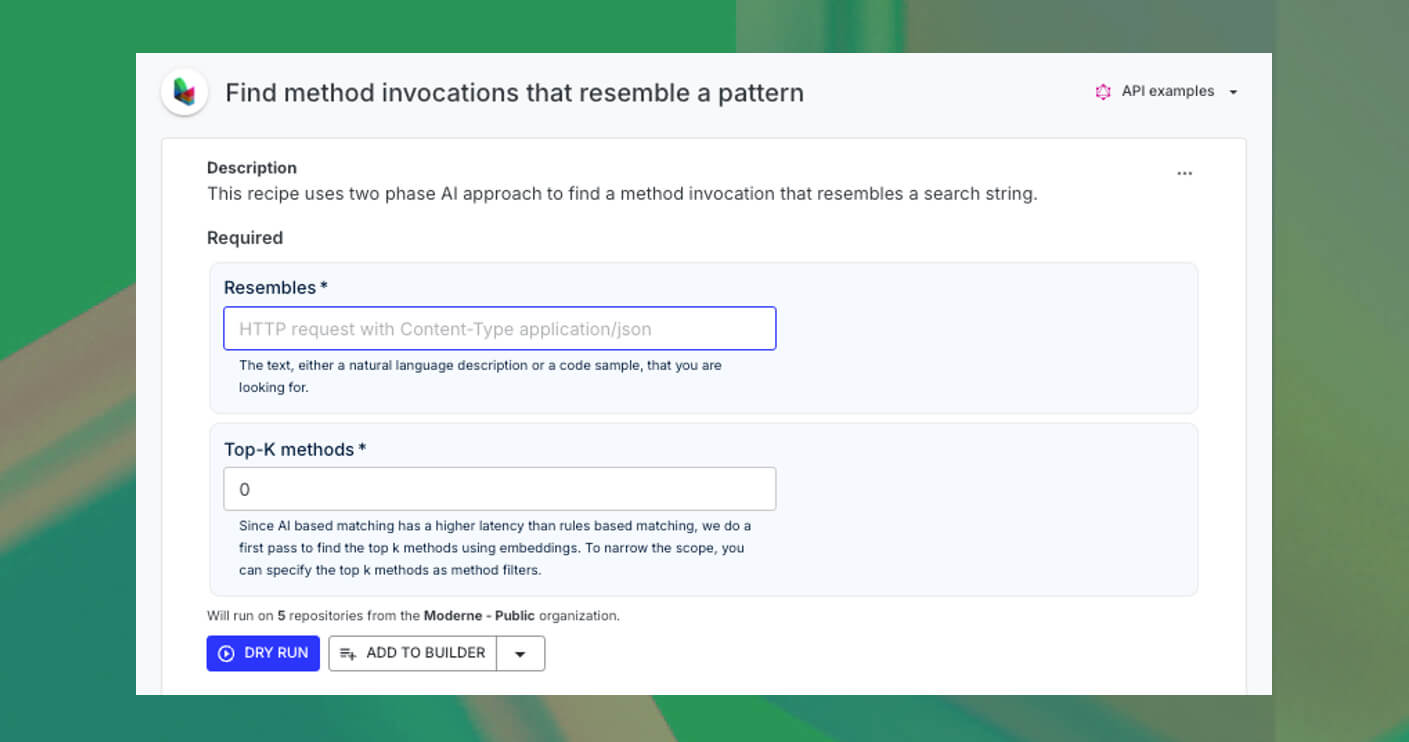
Let’s see the final recipe, “Find method invocations that resemble a pattern,” in action. To use the recipe in Moderne, specify a precise and concise method description in the “Resembles” option, avoiding verbs and using simple present tense. Adjust the “Top-K” option to balance search depth and speed, then click “Dry Run.”
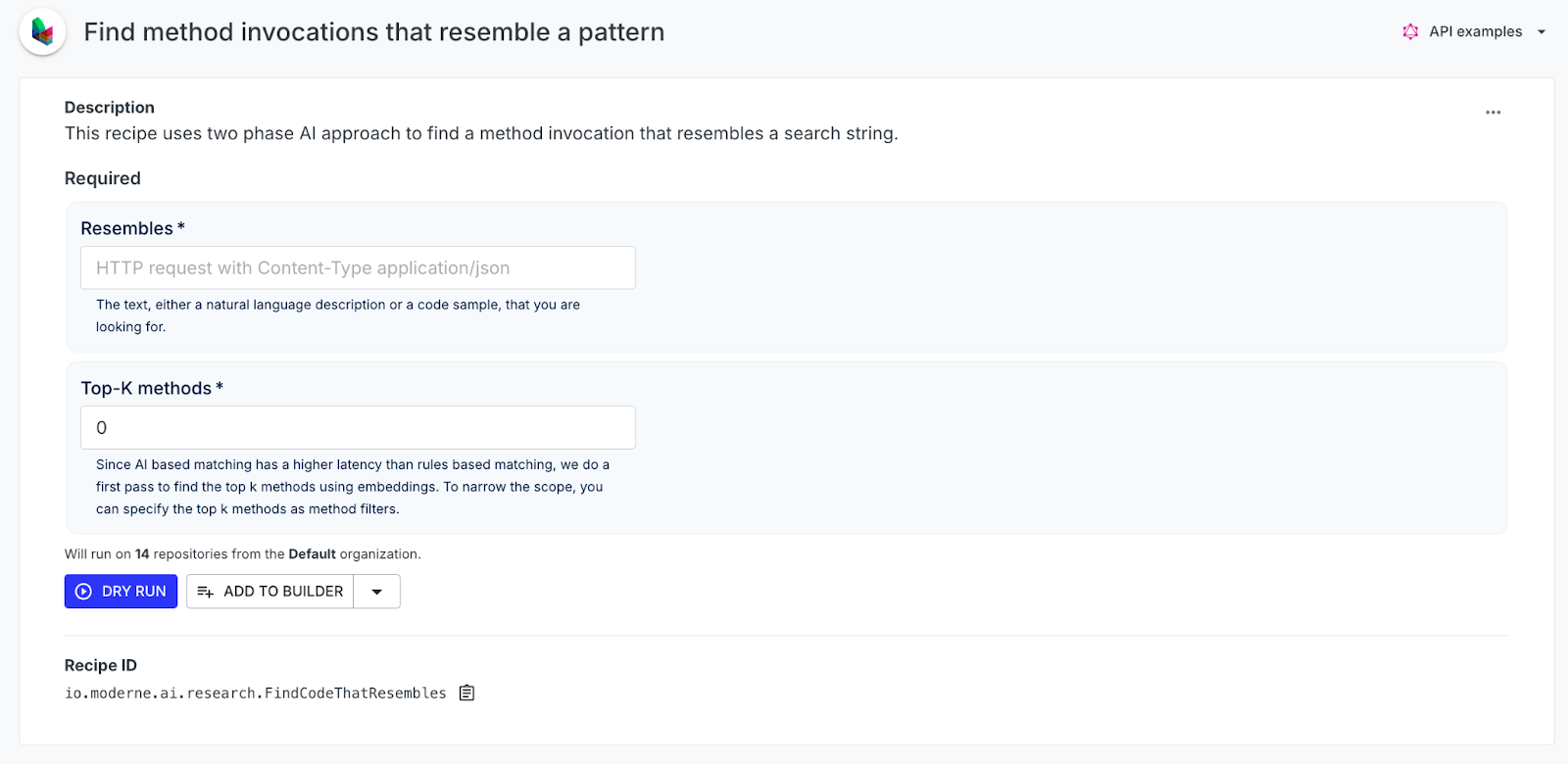
The final recipe run will show matching code snippets and file locations. You can further investigate the method patterns using the “Find uses method in code” recipe now that you know all the types. We also for convenience show how to get an automatically generated YAML recipe based on the results, where you can find all instances of a set of method patterns in a codebase.
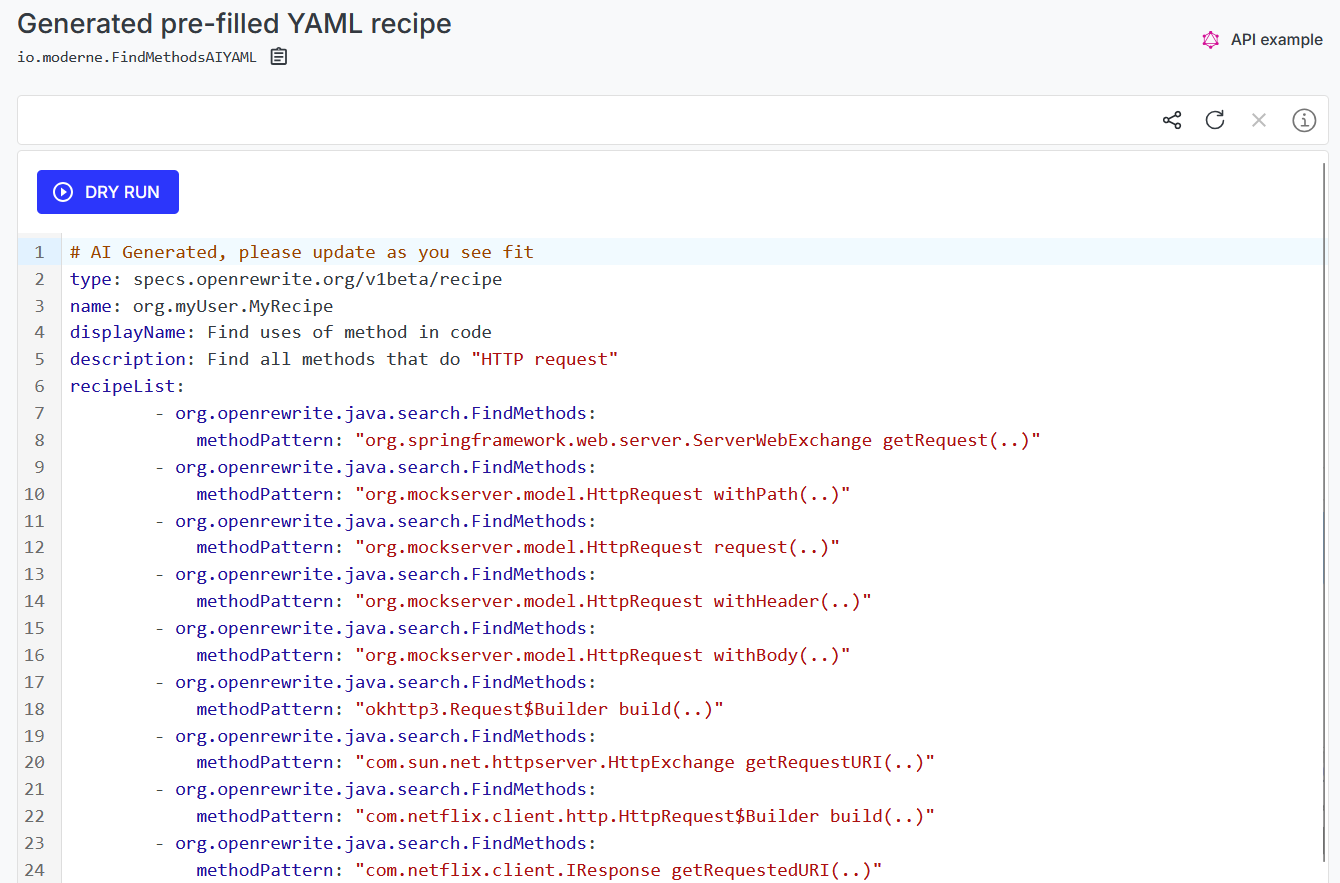
Learn more on how to use this recipe, and contact us to get started with Moderne’s AI-powered code search and refactoring.
Related posts


